- وµڈ览: 6176638 و¬،
-

و–‡ç« هˆ†ç±»
社هŒ؛版ه—
- وˆ‘çڑ„资讯 ( 0)
- وˆ‘çڑ„è®؛ه› ( 0)
- وˆ‘çڑ„é—®ç” ( 0)
هکو،£هˆ†ç±»
- 2013-05 ( 45)
- 2013-04 ( 98)
- 2013-03 ( 45)
- و›´ه¤ڑهکو،£...
وœ€و–°è¯„è®؛
-
vb2005xuï¼ڑ
è؟™و ·ن½ è·‘ن¸€ن¸ھ1000试试,هچ،ن¸چو»ن½
PHPه®çژ°و–گو³¢é‚£ه¥‘و•°هˆ— -
ykbj117ï¼ڑ
ن½ ن»¬çں¥éپ“هˆکç»چهچژن¹ˆï¼ںه°±وک¯هŒ—é‚®çڑ„ن¸€ن¸ھو•™وژˆï¼Œن¸“é—¨ç ”ç©¶WebRTCçڑ„资 ...
WebRTCن½“系结و„ -
huangbyeï¼ڑ
ه…¶ه®è؟™ن¹ںو²،ن»€ن¹ˆهچµç”¨ï¼پ
thinkphpè‡ھه®ڑن¹‰و ‡ç¾,viewç›´وژ¥و ‡ç¾è؟وژ¥و•°وچ® -
cofftechï¼ڑ
opencvو؛گç پï¼ڑhttp://www.eyesourceco ...
opencv资و–™ه’Œو–‡و،£ -
langke93ï¼ڑ
wangzhengyi_nopass.keyè؟™ن¸ھو€ژن¹ˆç”ںوˆگو²،ه†™
nginxوگه»؛httpsوœچهٹ،ه™¨
Linuxè°ƒه؛¦هںںè´ںè½½ه‡è،،-设è®،,ه®çژ°ه’Œه؛”用
第ن¸€éƒ¨هˆ†ï¼ڑLinuxè´ںè½½ه‡è،،çڑ„设è®،
ن¸€.è´ںè½½ه‡è،،çڑ„هژںهˆ™
1.ç،®ن؟و¯ڈن¸ھcpuو ¸ه؟ƒçڑ„è´ںè½½ه‡è،،ï¼›
2.هœ¨cpuه’Œcacheن»¥هڈٹه†…هکه¸ƒه±€çڑ„ه½±ه“چن¸‹هٹ وƒو‰§è،Œ1م€‚
ه¯¹ن؛ژن¸€èˆ¬ه¤ڑو ¸ه؟ƒcpuوƒ…ه†µï¼Œن»¥ن¸ٹن¸¤ن¸ھهژںهˆ™هڈ¯ن»¥ç®€è؟°ن¸؛ن¸‹é¢çڑ„هژںهˆ™ï¼ڑ
1.ه°½é‡ڈن¸چو‰§è،Œè؟›ç¨‹è؟پ移,ن»¥ç،®ن؟cacheçڑ„çƒه؛¦ï¼›
2.除éهگ„ن¸ھcpuçڑ„è´ںè½½ه·²ç»ڈن¸¥é‡چه¤±è،،,و‰§è،Œè´ںè½½ه‡è،،
ن؛Œ.ç³»ç»ںن»¥هڈٹcpuçڑ„و‹“و‰‘结و„
è؟™ن¸ھéپ“çگ†çœ‹ن¼¼ç®€هچ•ï¼Œç„¶è€Œه¦‚وœه¯¹ن؛ژن¸€ن¸ھه¤§ه‹çڑ„综هگˆç³»ç»ں,è¦پوƒ³è®¾è®،ن¸€ن¸ھ适用ن؛ژهگ„ç§چوƒ…ه†µçڑ„è´ںè½½ه‡è،،ن½“系,هچ´ن¸چوک¯ه¾ˆç®€هچ•م€‚Linuxه†…و ¸çڑ„è´ںè½½ه‡è،،设è®،çڑ„相ه½“ه®Œç¾ژم€‚ه¯¹ن؛ژè´ںè½½ه‡è،،,هڈ¯ن»¥هˆ†ن¸؛ن»¥ن¸‹ه‡ ç§چوƒ…ه†µï¼ڑ
ن»¥ç³»ç»ںه¤چو‚ه؛¦ن¸؛و ¸ه؟ƒçڑ„هˆ†ç±»
ï¼ڑ
وƒ…ه†µن¸€ï¼ڑcpuو— ن»»ن½•cache
è؟™ç§چوƒ…ه†µن¸‹ï¼Œéœ€è¦پéڑڈو—¶ن؟وŒپهگ„cpuن¸ٹè؟گè،Œçڑ„è؟›ç¨‹و•°é‡ڈçڑ„ه‡è،،
وƒ…ه†µن؛Œï¼ڑه¤ڑه¤„çگ†ه™¨ï¼Œو¯ڈن¸ھه¤„çگ†ه™¨وœ‰ه¤„çگ†ه™¨ç‹¬ن؛«çڑ„cache
è؟™ç§چوƒ…ه†µن¸‹ï¼Œè؟›è،Œè´ںè½½ه‡è،،ن¼ڑه½±ه“چه¤„çگ†ه™¨çڑ„cacheهˆ©ç”¨çژ‡ï¼Œè´ںè½½ه‡è،،ه¸¦و¥çڑ„و•ˆç›ٹن¼ڑ被cacheهˆ·و–°çڑ„ه¼€é”€وٹµو¶ˆوژ‰ن¸€éƒ¨هˆ†وˆ–ه¤§éƒ¨هˆ†م€‚
وƒ…ه†µن¸‰ï¼ڑه¤ڑه¤„çگ†ه™¨ï¼Œو¯ڈن¸ھه¤„çگ†ه™¨وœ‰ه¤ڑن¸ھه¤„çگ†ه™¨و ¸ه؟ƒï¼Œو¯ڈن¸ھو ¸ه؟ƒوœ‰ç‹¬ن؛«çڑ„ن¸€ç؛§cache,هگŒن¸€ه¤„çگ†ه™¨çڑ„ه¤ڑن¸ھو ¸ه؟ƒوœ‰ه…±ن؛«çڑ„ن؛Œç؛§ï¼Œن¸‰ç؛§cache
è؟™ç§چوƒ…ه†µن¸‹ï¼Œوƒ…ه†µن؛Œوک¯è¦پ考虑çڑ„,然而ه¯¹ن؛ژهگŒن¸€ه¤„çگ†ه™¨çڑ„ن¸چهگŒو ¸ه؟ƒن¹‹é—´ç”±ن؛ژهکهœ¨ه…±ن؛«çڑ„ن؛Œç؛§cache,ه¤ڑن¸ھو ¸ه؟ƒن¹‹é—´çڑ„è´ںè½½ه‡è،،وٹµو¶ˆوژ‰çڑ„cacheهˆ©ç”¨çژ‡و”¶ç›ٹè؟œè؟œه°ڈن؛ژن¸چهگŒه¤„çگ†ه™¨ن¹‹é—´çڑ„è´ںè½½ه‡è،،ن½œهگŒو ·çڑ„ن؛‹وƒ…م€‚
وƒ…ه†µه››ï¼ڑوƒ…ه†µن¸‰çڑ„ه‰چوڈگن¸‹ï¼Œو¯ڈن¸€ن¸ھه¤„çگ†ه™¨çڑ„و¯ڈن¸€ن¸ھو ¸ه؟ƒهڈˆه¼€هگ¯ن؛†è¶…ç؛؟程(Intelوœ¯è¯)م€‚
ç”±ن؛ژ超ç؛؟程ن½؟用هگŒن¸€ه¥—è®،算资و؛گ,ن¸”ه…±ن؛«cache,ه› و¤ه…¶ن¸ٹçڑ„è´ںè½½ه‡è،،ه‡ ن¹ژن¸چن¼ڑه½±ه“چcacheهˆ©ç”¨çژ‡م€‚然而ه¦‚وœè¶…ç؛؟程و ¸çڑ„è°ƒه؛¦ç®—و³•ن»¥هڈٹو“چن½œç³»ç»ںçڑ„è°ƒه؛¦ç®—و³•è®¾è®،çڑ„ن¸چه¥½ï¼Œé€ وˆگن¸€ن¸ھو“چن½œç³»ç»ںç؛؟程é•؟وœںن½؟用超ç؛؟程و ¸ï¼Œن¹ںن¼ڑé€ وˆگن¸ٹن¸€ن¸ھهˆ‡وچ¢ه‡؛çڑ„و“چن½œç³»ç»ںç؛؟程çڑ„cache被وŒ¤ه‡؛هژ»ï¼Œéپ—و†¾çڑ„وک¯ï¼Œن¸€èˆ¬وƒ…ه†µن¸‹وˆ‘ن»¬و— هٹ›ن¼کهŒ–و“چن½œç³»ç»ںçڑ„è°ƒه؛¦ç®—و³•ï¼Œه¹¶ن¸”و— و³•وژ¥è§¦cpuçڑ„smtè°ƒه؛¦ç®—و³•م€‚
وƒ…ه†µن؛”ï¼ڑوƒ…ه†µن¸€هˆ°ه››çڑ„ه‰چوڈگن¸‹ï¼Œه¢هٹ ن¸چه¯¹ç§°ه†…هکم€‚
è؟™ç§چوƒ…ه†µن¸‹ï¼Œè´ںè½½ه‡è،،ه¯¹cacheهˆ©ç”¨çژ‡çڑ„ه½±ه“چوک¾ç„¶وک¯ن¸چهڈ¯éپ؟ه…چçڑ„,هگŒو—¶è؟کن¼ڑه½±ه“چè®؟é—®ه†…هکçڑ„و—¶é—´ï¼Œن¹ںه°±وک¯ه†…هکçڑ„هˆ©ç”¨و•ˆçژ‡ï¼Œè؟™ه°±وک¯NUMAçڑ„وƒ…ه†µ...
ن»¥ن¸ٹن؛”ç§چوƒ…ه†µهں؛وœ¬ه°±وک¯ن¸€ن¸ھه¤چو‚ç³»ç»ںن»ژوœ€ç®€هچ•هˆ°وœ€ه¤چو‚çڑ„وژ’هˆ—,ه¦‚وœوˆ‘ن»¬ن¸چن»¥و•´ن¸ھç³»ç»ںن¸؛و ¸ه؟ƒï¼Œè€Œن»¥ه¤„çگ†ه™¨ن¸؛و ¸ه؟ƒï¼Œ
ه؛”该وک¯ن»¥ن¸‹ه››ç§چوژ’هˆ—وƒ…ه†µï¼ڑ
ن»¥ه¤„çگ†ه™¨ن¸؛و ¸ه؟ƒçڑ„هˆ†ç±»ï¼ڑ
وƒ…ه†µن¸€ï¼ڑهچ•ن¸ھه¤„çگ†ه™¨ه¼€هگ¯è¶…ç؛؟程
è؟™وک¯وˆ‘ن»¬ç†ںçں¥çڑ„SMTوƒ…ه†µ
وƒ…ه†µن؛Œï¼ڑهچ•ن¸ھه¤„çگ†ه™¨ه¤ڑن¸ھو ¸ه؟ƒ
è؟™وک¯وˆ‘ن»¬ç†ںçں¥çڑ„ه¤ڑو ¸ه¤„çگ†ه™¨وƒ…ه†µ
وƒ…ه†µن¸‰ï¼ڑه¤ڑن¸ھه¤„çگ†ه™¨
è؟™وک¯وˆ‘ن»¬ç†ںçں¥çڑ„SMPوƒ…ه†µ
وƒ…ه†µه››ï¼ڑه¤ڑه¤„çگ†ه™¨ï¼Œه¤ڑه†…هکهںں
è؟™وک¯وˆ‘ن»¬ç†ںçں¥çڑ„NUMAوƒ…ه†µï¼Œه†…هکه¯¹ن؛ژن¸چهگŒçڑ„ه¤„çگ†ه™¨و¥è®²ï¼Œه…¶è®؟é—®و•ˆçژ‡وک¯ن¸چهگŒçڑ„م€‚
ن¸‰.è´ںè½½ه‡è،،هں؛ç،€è®¾و–½ن»¥هڈٹcpuو‹“و‰‘结و„(é™و€پ设و–½)
è؟›ç¨‹هœ¨ن¸چهگŒcpuن¹‹é—´çڑ„è؟پ移ه’Œcacheهˆ©ç”¨çژ‡و€»çڑ„و¥è¯´وک¯ه¯¹ç«‹çڑ„,ه¹¶ن¸”و ¹وچ®و؛گcpuه’Œç›®çڑ„cpuن¹‹é—´çڑ„ه…³ç³»ن¸چهگŒè؟™ç§چه¯¹ç«‹çڑ„程ه؛¦ ن¹ںن¸چهگŒم€‚ ç”±ن؛ژè؟›ç¨‹è؟پ移وک¯هں؛ن؛ژcpuçڑ„,而cpuوœ€ه°ڈç؛§هˆ«çڑ„ه°±وک¯è¶…ç؛؟程ه¤„çگ†ه™¨çڑ„ن¸€ن¸ھsmtو ¸ï¼Œو¬،ه°ڈçڑ„ن¸€ç؛§ه°±وک¯ن¸€ن¸ھه¤ڑو ¸cpuçڑ„و ¸ï¼Œç„¶هگژه°±وک¯ن¸€ن¸ھ物çگ†cpuه°پ装,ه†چه¾€هگژه°±وک¯cpuéکµهˆ—,و ¹وچ®è؟™ن؛›cpuç؛§هˆ«çڑ„ن¸چهگŒï¼ŒLinuxه°†و‰€وœ‰هگŒن¸€ç؛§هˆ«çڑ„cpuه½’ن¸؛ن¸€ن¸ھ“调ه؛¦ç»„â€ï¼Œç„¶هگژه°†هگŒن¸€ç؛§هˆ«çڑ„و‰€وœ‰çڑ„è°ƒه؛¦ç»„组وˆگن¸€ن¸ھ“调ه؛¦هںںâ€ï¼Œ è´ںè½½ه‡è،،首ه…ˆهœ¨è°ƒه؛¦هںںçڑ„هگ„ن¸ھè°ƒه؛¦ç»„ن¹‹é—´è؟›è،Œï¼Œç„¶هگژه†چهœ¨وœ€ن½ژن¸€ç؛§çڑ„cpuن¸ٹè؟›è،Œï¼Œو³¨و„ڈè´ںè½½ه‡è،،وک¯هں؛ن؛ژوœ€ه°ڈن¸€ç؛§çڑ„cpuçڑ„م€‚و•´ن¸ھو¶و„ه¦‚ن¸‹ه›¾و‰€ç¤؛ï¼ڑ
ه››.è´ںè½½ه‡è،،ç®—و³•هˆ†وگ(هٹ¨و€پè،¨çژ°)
è؟پ移ن¸€ن¸ھè؟›ç¨‹çڑ„ن»£ن»·ه°±وک¯ه‰ٹه¼±cacheçڑ„ن½œç”¨م€‚ ه› و¤ï¼Œهڈھè¦پهœ¨و‹¥وœ‰cacheçڑ„ه¤„çگ†ه™¨ن¹‹é—´è؟پ移è؟›ç¨‹ï¼Œهٹ؟ه؟…ن¼ڑن»که‡؛è؟™ن¸ھن»£ن»·ï¼Œه› و¤هœ¨è®¾è®،ن¸ه؟…然需è¦پن¸€ç§چ“éک»هٹ›â€و¥ه°½é‡ڈن¸چهپڑè؟›ç¨‹è؟پ移,除éن¸‡ن¸چه¾—ه·²ï¼پè؟™ç§چ“éک»هٹ›â€ه°±وک¯è´ںè½½ه‡è،،هژںهˆ™2ن¸çڑ„“هٹ وƒâ€ç³»و•°م€‚
1).هژ†هڈ²è´ںè½½ه€¼çڑ„ه½±ه“چ
ن¸؛éک²و¢ه¤„çگ†ه™¨è´ںè½½و›²ç؛؟çڑ„ن¸ٹن¸‹é¢ 簸,用هژ†هڈ²ه€¼و¥هٹ وƒه½“ه‰چه€¼وک¯ن¸€ن¸ھن¸چé”™çڑ„و–¹ه¼ڈ ,ن¹ںه°±وک¯è¯´ï¼Œو‰€è°“çڑ„è´ںè½½و›²ç؛؟ن¸چه†چهں؛ن؛ژو—¶é—´ç‚¹ ,而وک¯هں؛ن؛ژو—¶é—´و®µ م€‚ 然而هژ†هڈ²è´ںè½½ه€¼ه¯¹و€»è´ںè½½çڑ„ه½±ه“چ肯ه®ڑو²،وœ‰ه½“ه‰چçڑ„è´ںè½½ه€¼ه¯¹و€»è´ںè½½çڑ„ه½±ه“چه¤§ï¼Œن¸€ن¸ھو—¶é—´ç‚¹çڑ„è´ںè½½ه€¼éڑڈç€و—¶é—´çڑ„وµپé€ï¼Œه¯¹è´ںè½½ه‡è،،و—¶و€»è´ںè½½çڑ„è®،ç®—çڑ„ه½±ه“چه؛”该é€گو¸گه‡ڈه°ڈم€‚ه› و¤Linuxçڑ„è´ںè½½ه‡è،،ه™¨è®¾è®،ن؛†ن¸€ن¸ھه…¬ه¼ڈن¸“门用ن؛ژè´ںè½½ه‡è،،è؟‡ç¨‹ن¸ه¯¹cpuو€»è´ںè½½çڑ„è®،ç®—م€‚该ه…¬ه¼ڈه¦‚ن¸‹ï¼ڑ
total_load=(previous_load*(delta-1)+nowa_load)/delta
ه…¶ن¸deltaوک¯ن¸€ن¸ھهڈ¯هڈکçڑ„ç³»و•°ï¼Œهœ¨linux 2.6.18ن¸è®¾ç½®ن؛†3ن¸ھdelta,هˆ†هˆ«ن¸؛1,2,4,ه½“然è؟کهڈ¯ن»¥و›´ه¤ڑ,و¯”ه¦‚é«کن¸€ن؛›ç‰ˆوœ¬çڑ„ه†…و ¸ن¸deltaçڑ„هڈ–ه€¼وœ‰CPU_LOAD_IDX_MAXç§چ,CPU_LOAD_IDX_MAXç”±ه®ڈو¥ه®ڑن¹‰م€‚و¯”ه¦‚ه½“deltaن¸؛2çڑ„و—¶ه€™ï¼Œن¸ٹè؟°ه…¬ه¼ڈوˆگن¸؛ï¼ڑ
total_load=(previous_load+nowa_load)/2
相ه½“ن؛ژهژ†هڈ²ه€¼هچ وچ®و•´ن¸ھloadه€¼ن¸€هچٹ,而ه½“ه‰چه€¼هچ وچ®هڈ¦ن¸€هچٹم€‚
2).و³¢ه³°/و³¢è°·çڑ„ه¹³و»‘هŒ–
让هژ†هڈ²ه€¼هڈ‚ن¸ژè®،ç®—و€»è´ں载解ه†³ن؛†هگŒن¸€و،è´ںè½½و›²ç؛؟é¢ ç°¸çڑ„é—®é¢ک,ن½†وک¯هœ¨è´ںè½½ه‡è،،و—¶وک¯و¯”较ن¸¤و،è´ںè½½و›²ç؛؟هگŒن¸€و—¶é—´ç‚¹ن¸ٹçڑ„ه€¼ ,ه½“ن؛Œè€…相ه·®ه¤§ن؛ژن¸€ن¸ھéک€ه€¼و—¶ï¼Œه®و–½è؟›ç¨‹è؟پ移م€‚ ن¸؛ن؛†هپڑهˆ°â€œه°½é‡ڈن¸چهپڑè؟›ç¨‹è؟پ移â€è؟™ن¸ھهژںهˆ™ï¼Œه؟…é،»ه°†ن¸¤و،è´ںè½½و›²ç؛؟çڑ„و³¢ه³°ه’Œو³¢è°·ه¹³و»‘وژ‰م€‚ ه¦‚وœè؟›ç¨‹è؟پ移و؛گcpuçڑ„è´ںè½½و›²ç؛؟و¤و—¶و£ه¥½هœ¨و³¢ه³°ï¼Œç›®çڑ„cpuçڑ„è´ںè½½و›²ç؛؟و¤و—¶و£ه¥½هœ¨و³¢è°·ï¼Œو¤و—¶ه°±éœ€è¦په°†و³¢ه³°ه’Œو³¢è°·ه‰ٹه¹³ï¼Œè®©و؛گcpuçڑ„è´ںè½½ن¸‹é™چa,而目çڑ„cpuçڑ„è´ںè½½ن¸ٹهچ‡b,è؟™و ·ه®ƒن»¬ن¹‹é—´çڑ„è´ںè½½ه·®ه°±ن¼ڑه‡ڈه°‘a+b,è؟™ن¸ھ“éک»هٹ›â€è¶³ن»¥éک»و¢ه¾ˆه¤ڑçڑ„è؟›ç¨‹è؟پ移و“چن½œم€‚
3).è´ںè½½و›²ç؛؟ه¹³و»‘و“چن½œçڑ„هں؛ه‡†
è´ںè½½ه‡è،،ه¹³و»‘و“چن½œو—¶éœ€è¦پن¸¤ن¸ھه€¼ï¼Œهچ³ن¸ٹè؟°çڑ„aه’Œb,è؟™ن¸¤ن¸ھه€¼ه†³ه®ڑن؛†ه‰ٹه¹³و³¢ه³°/و³¢è°·çڑ„ه¹…ه؛¦ï¼Œه¹…ه؛¦è¶ٹه¤§ï¼Œéک»ç¢چè´ںè½½ه‡è،،çڑ„“هٹ›ه؛¦â€ن¹ںه°±è¶ٹه¤§ï¼Œهڈچن¹‹â€œهٹ›ه؛¦â€ن¹ںه°±è¶ٹه°ڈم€‚و ¹وچ®هڈ‚ن¸ژè´ںè½½ه‡è،،çڑ„cpuçڑ„ه±‚و¬،ç؛§هˆ«çڑ„ن¸چهگŒï¼Œè؟™ç§چه¹…ه؛¦ه؛”该ن¸چهگŒï¼Œه¹¸è؟گçڑ„وک¯ï¼Œهڈ¯ن»¥و ¹وچ®è°ƒو•´â€œè´ںè½½ه‡è،،è؟‡ç¨‹ن¸ه¯¹cpuو€»è´ںè½½çڑ„è®،ç®—ه…¬ه¼ڈâ€ن¸çڑ„deltaو¥ه½±ه“چه¹…ه؛¦çڑ„ه¤§ه°ڈ, è؟™و ·ï¼Œ1)ه’Œ2)ه°±هœ¨è؟™ç‚¹ن¸ٹèژ·ه¾—ن؛†ç»ںن¸€م€‚ه¯¹ن؛ژç›®çڑ„cpu,هڈ–è®،ç®—ه¾—هˆ°çڑ„total_loadه’Œnowa_loadن¹‹é—´çڑ„وœ€ه¤§ه€¼ï¼Œè€Œه¯¹ن؛ژو؛گcpu,هˆ™هڈ–ن؛Œè€…وœ€ه°ڈه€¼م€‚هڈ¯ن»¥çœ‹ه‡؛,هœ¨ه…¬ه¼ڈن¸ï¼Œه¦‚وœdeltaç‰ن؛ژ1,هˆ™ن¸چو‰§è،Œه‰ٹو³¢ه³°/و³¢è°·و“چن½œï¼Œè؟™é€‚用ن؛ژsmtçڑ„وƒ…ه†µï¼Œdeltaè¶ٹه¤§ï¼Œهژ†هڈ²è´ںè½½ه€¼çڑ„ه½±ه“چن¹ںه°±è¶ٹه¤§ï¼Œه‰ٹو³¢ه³°/و³¢è°·هگژçڑ„و؛گcpuè´ںè½½و›²ç؛؟ه’Œç›®çڑ„cpuè´ںè½½و›²ç؛؟çڑ„ه·®ه€¼و›²ç؛؟è¶ٹ趋ن؛ژه¹³و»‘,è؟™و ·ه°±è¶ٹ能éک»و¢è´ںè½½ه‡è،،و“چن½œ(ه·®هˆ†ç®—و³•....)م€‚
4).è‡ھن¸‹è€Œن¸ٹçڑ„éپچهژ†و–¹ه¼ڈ
Linuxهœ¨هں؛ن؛ژè°ƒه؛¦هںںè؟›è،Œè´ںè½½ه‡è،،çڑ„و—¶ه€™é‡‡ç”¨çڑ„وک¯è‡ھن¸‹è€Œن¸ٹçڑ„éپچهژ†و–¹ه¼ڈ,è؟™و ·ه°±ن¼که…ˆهœ¨ه¯¹cacheه½±ه“چوœ€ه°ڈçڑ„cpuن¹‹é—´è؟›è،Œè´ںè½½ه‡è،،,هگŒو—¶è؟™ç§چه‡è،،و“چن½œن¼ڑه¢هٹ وœ¬cpuçڑ„è´ں载,هڈچè؟‡و¥هœ¨و¯”较é«کçڑ„è°ƒه؛¦هںںç؛§هˆ«ن¸ٹوœ‰هٹ›çڑ„éک»و¢ن؛†ه¯¹cacheه½±ه“چه¾ˆه¤§çڑ„cpuن¹‹é—´çڑ„è´ںè½½ه‡è،،م€‚ وˆ‘ن»¬çں¥éپ“,调ه؛¦هںںوک¯ن»ژه¯¹cacheه½±ه“چوœ€ه°ڈçڑ„وœ€ه؛•ه±‚هگ‘é«که±‚و„ه»؛çڑ„م€‚
5).结è®؛
éڑڈç€cpuç؛§هˆ«çڑ„وڈگé«ک,由ن؛ژè´ںè½½ه‡è،،ه¯¹cacheهˆ©ç”¨çژ‡çڑ„ه½±ه“چé€گو¸گه¢ه¤§ï¼Œâ€œéک»هٹ›â€ن¹ںه؛”该é€گو¸گهٹ ه¤§ï¼Œه› و¤è´ںè½½ه‡è،،ه¯¹ه؛”è°ƒه؛¦هںںن½؟用çڑ„deltaن¹ںه؛”该ه¢هٹ م€‚
ç®—و³•çڑ„و ¹وœ¬è¦پ点وک¯ن»€ن¹ˆه‘¢ï¼ںç”»ه¹…ه›¾ه°±ن¸€ç›®ن؛†ç„¶ن؛†ï¼Œdeltaè¶ٹه¤§ï¼Œè´ںè½½ه€¼هڈ—هژ†هڈ²ه€¼çڑ„ه½±ه“چè¶ٹه¤§ï¼Œه› و¤وŒ‰ç…§ه…¬ه¼ڈو‰€ç¤؛,هڈھوœ‰وŒپç»هچ•è°ƒé€’ه¢
çڑ„cpuè´ں载,هœ¨و؛گcpu选و‹©و—¶و‰چن¼ڑ被选ن¸ï¼Œهپ¶ç„¶ن¸€و¬،çڑ„é«کè´ںè½½ه¹¶ن¸چ足ن»¥ه¼•èµ·ه…¶ن¸ٹçڑ„è؟›ç¨‹è؟پ移至هˆ«ه¤„,相ه؛”çڑ„,هڈھوœ‰è´ںè½½وŒپç»هچ•è°ƒé€’ه‡ڈ
,و‰چن¼ڑه¼•èµ·ه…¶ه®ƒcpuن¸ٹçڑ„è؟›ç¨‹è؟پ移至و¤ï¼Œè؟™و£ن½“çژ°ن؛†è´ںè½½ن»¥ن¸€ن¸ھو—¶é—´و®µè€Œن¸چوک¯ن¸€ن¸ھو—¶é—´ç‚¹ن¸؛ç»ںè®،ه‘¨وœںï¼پ
而ç؛§هˆ«è¶ٹé«کçڑ„cpué—´çڑ„è؟›ç¨‹è؟پ移,需è¦پçڑ„“éک»هٹ›â€è¶ٹه¤§ï¼Œه› و¤ه°±è¶ٹهڈ—هژ†هڈ²ه€¼çڑ„ه½±ه“چ,ه› ن¸؛هڈھè¦پهژ†هڈ²ن¸وœ‰ن¸€و¬،è´ںè½½ه¾ˆه°ڈ,ه°±ن¼ڑه¾ˆوکژوک¾çڑ„هڈچه؛”هœ¨ه½“ه‰چ,هگŒو ·çڑ„éپ“çگ†ï¼Œهژ†هڈ²ن¸وœ‰ن¸€و¬،çڑ„è´ںè½½ه¾ˆه¤§ï¼Œن¹ںه¾ˆه®¹وک“هڈچوک هœ¨ه½“ه‰چï¼›هڈچن¹‹ï¼Œو‰€éœ€â€œéک»هٹ›â€è¶ٹه°ڈ,ه°±è¶ٹه®¹وک“هڈ—ه½“ه‰چè´ںè½½ه€¼çڑ„ه½±ه“چ,وپ端çڑ„وƒ…ه†µن¸‹ï¼Œè¶…ç؛؟程çڑ„ن¸چهگŒé€»è¾‘cpuن¹‹é—´çڑ„è´ںè½½è®،ç®—ه…¬ه¼ڈن¸deltaن¸؛1,ه› و¤ه®ƒن»¬çڑ„è´ںè½½è®،算结وœه®Œه…¨ه°±وک¯è¯¥cpuçڑ„ه½“ه‰چè´ںè½½ï¼پ
结è®؛وœ‰ن¸‰ï¼ڑ
5.1).é€ڑè؟‡â€œè´ںè½½ه‡è،،è؟‡ç¨‹ن¸ه¯¹cpuو€»è´ںè½½çڑ„è®،ç®—ه…¬ه¼ڈâ€ه¹³و»‘ن؛†هچ•ç‹¬cpuçڑ„è´ںè½½و›²ç؛؟,ن½؟ن¹‹ن¸چهڈ—çھپهڈکçڑ„ه½±ه“چ,ه¹³و»‘程ه؛¦و ¹وچ®deltaه¾®è°ƒ
5.2).é€ڑè؟‡â€œه‰ٹوژ‰و³¢ه³°/و³¢è°·â€ه¹³و»‘ن؛†و؛گcpuه’Œç›®çڑ„cpuè´ںè½½و›²ç؛؟هœ¨è´ںè½½ه‡è،،è؟™ن¸ھو—¶é—´ç‚¹çڑ„ه·®ه€¼ï¼Œه°½هڈ¯èƒ½éک»و¢è؟›ç¨‹è؟پ移,éک»و¢ç¨‹ه؛¦و ¹وچ®deltaه¾®è°ƒ
5.3).و‰§è،Œè´ںè½½ه‡è،،çڑ„è؟‡ç¨‹ن¸ï¼Œن¸€è½®è´ںè½½ه‡è،،هœ¨و¯ڈن¸€ه±‚çڑ„و•ˆوœéœ€è¦پéڑڈç€ç؛§هˆ«çڑ„هچ‡é«ک而é™چن½ژ,è؟™é€ڑè؟‡è‡ھن¸‹è€Œن¸ٹçڑ„éپچهژ†و–¹ه¼ڈو¥ه®Œوˆگ
6).ه¼•ç”³
total_loadçڑ„è®،ç®—ه…¬ه¼ڈه®é™…ن¸ٹن½؟用ن؛†ن¸€ن¸ھو•°هˆ—,该و•°هˆ—وک¯ن¸€ن¸ھ“ç‰و¯”و•°هˆ—+ه¾®و‰°و•°هˆ—â€çڑ„ه’Œو•°هˆ—, ç‰و¯”çڑ„و¯”ه€¼çڑ„هˆ†و¯چه†³ه®ڑç€و•°هˆ—çڑ„ه¹³و»‘程ه؛¦ï¼Œè€Œه¾®و‰°و•°هˆ—هˆ™وک¯cpuçڑ„ه½“ه‰چçœںه®è´ں载,ه®ƒو ¹وچ®deltaçڑ„هڈ–ه€¼ن¸چهگŒه¯¹و•´ن¸ھcpuçڑ„è´ںè½½ه½±ه“چن¸چهگŒï¼Œن¸؛ن؛†è؟ç»هŒ–و•°هˆ—,وˆ‘ن»¬è®¾è؟™ن¸¤ن¸ھو•°هˆ—ن¸؛ه‡½و•°f(x)ه’Œg(x),è¯پوکژه¦‚ن¸‹ï¼ڑ

6.1).ç®—و³•و”¹è؟›
ن¸چ能ن»ژdeltaن¸ه¾—هˆ°éڑڈç€dçڑ„ه¢هٹ ,éک»ç¢چè´ںè½½ه‡è،،çڑ„هٹ›ه؛¦ه°†هٹ ه¤§è؟™ن¸ھن؛‹ه®è™½ç„¶هœ¨وٹ€وœ¯ن¸ٹé€ڑè؟‡è‡ھن¸‹è€Œن¸ٹçڑ„éپچهژ†و–¹ه¼ڈ解ه†³ن؛†ï¼Œç„¶è€Œè؟™ن½؟ه¾—ç®—و³•ن¾èµ–ن؛†ن¸€ن¸ھو“چن½œو–¹ه¼ڈ,è؟™هœ¨و•°ه¦هچ´ن¸چوک¯ه¾ˆه®Œç¾ژ, ه› و¤هڈ¯ن»¥و”¹è؟›ï¼Œه¼•ه…¥ن¸€ن¸ھهڈ‚و•°kو¥ه¾®è°ƒg(x) ,而ن¸چوک¯ن¾èµ–dو¥ه¾®è°ƒï¼Œه¦‚وœé…چç½®kه’Œd相ç‰ï¼Œé‚£ن¹ˆو–°ç®—و³•ه°†ه›é€€هˆ°è€پç®—و³•ï¼ڑ

وœ‰ن؛†و–°çڑ„è´ںè½½è®،ç®—ه…¬ه¼ڈ,وˆ‘ن»¬هڈ¯ن»¥وژ§هˆ¶ن¸€ن¸ھهڈکé‡ڈk,然هگژه¾—çں¥ï¼Œéڑڈç€dçڑ„ه¢هٹ ,è´ںè½½ه‡è،،ه®é™…هڈ‘ç”ںçڑ„هڈ¯èƒ½و€§ه°†é™چن½ژم€‚
ن؛”.Linuxè´ںè½½ه‡è،،çڑ„ç±»ه‹ن»¥هڈٹو—¶وœ؛
1.ه‘¨وœںو€§ه؟™è´ںè½½ه‡è،،ï¼ڑهœ¨و—¶é’ںن¸و–ن¸é’ˆه¯¹ه½“ه‰چcpu调用,è´ںè½½è®،ç®—و—¶و›´ه¤ڑهڈ—هˆ°هژ†هڈ²ه€¼çڑ„ه½±ه“چï¼›
2.ه‘¨وœںو€§ç©؛é—²è´ںè½½ه‡è،،ï¼ڑه½“ه‰چcpuن¸ٹو²،وœ‰è؟›ç¨‹هڈ¯è؟گè،Œو—¶è°ƒç”¨ï¼Œé€‚ه½“ه‡ڈه°‘هژ†هڈ²ه€¼çڑ„ه½±ه“چ,ه’Œه؟™è´ںè½½ه‡è،،çڑ„ه‘¨وœں相ه·®ن¸€ن¸ھbusy_factorه› هگ(该ه› هگهڈ¯é…چç½®)م€‚
3.ه”¤é†’è؟›ç¨‹è´ںè½½ه‡è،،ï¼ڑLinuxه†…و ¸ه€¾هگ‘ن؛ژوœ¬هœ°ه”¤é†’è؟›ç¨‹ï¼Œن¹ںه°±وک¯è¯´ه°†è؟›ç¨‹ه”¤é†’هœ¨وœ¬cpuن¸ٹم€‚هœ¨ç½‘络ه؛”用ن¸ï¼Œè؟™وک¾ه¾—ه°¤ن¸؛é‡چè¦پ,ن¼—و‰€ه‘¨çں¥ï¼Œç½‘هچ،ن¸و–وںگن¸€ن¸ھcpu,该cpuه¤„çگ†è½¯ن¸و–,软ن¸و–ه¤„çگ†هچڈè®®و ˆï¼Œهœ¨cpuçڑ„ه¤„çگ†è؟‡ç¨‹ن¸ç½‘络و•°وچ®ç›¸ه؛”è؟›ه…¥cache,و¤و—¶ه”¤é†’用وˆ·و€پè؟›ç¨‹ç»§ç»ه¤„çگ†ه؛”用و•°وچ®ï¼Œه¦‚وœوک¯وœ¬هœ°ه”¤é†’çڑ„è¯ï¼Œه؛”用程ه؛ڈهڈ¯ن»¥وœ‰و•ˆهˆ©ç”¨cpuن¸ه·²ç»ڈ被ه†…و ¸è½½ه…¥çڑ„cacheم€‚
4.è؟›ç¨‹و–°هˆ›ه»؛çڑ„و—¶ه€™ن¼ڑè؟›è،Œè´ںè½½ه‡è،،,ه› و¤ه¤ڑن؛†ن¸€ن¸ھè؟›ç¨‹هڈ¯èƒ½ن¼ڑه¼•èµ·è´ںè½½ه¤±è،،م€‚
5.è؟›ç¨‹è°ƒç”¨execçڑ„و—¶ه€™ن¼ڑè؟›è،Œè´ںè½½ه‡è،،,ه’Œ4ن¸€و ·ï¼Œè؟™ن¸¤ç§چè´ںè½½ه‡è،،都وک¯â€œè‡ھè´ںè½½â€ه‡è،،,ن¹ںه°±وک¯è¦پن¸؛è‡ھه·±é€‰و‹©ن¸€ن¸ھcpuو¥è؟گè،Œ
6.ه½“ه‰چcpu马ن¸ٹè؟›ه…¥idleçڑ„و—¶ه€™ï¼Œن¼ڑè؟›è،Œè´ںè½½ه‡è،،
7.pushه¹³è،،,è؟™وک¯ن¸€ç§چه°†وœ¬هœ°è؟›ç¨‹â€œوژ¨â€ç»™ه…¶ن»–cpuçڑ„è´ںè½½ه‡è،،و–¹ه¼ڈ
第ن؛Œéƒ¨هˆ†ï¼ڑLinuxè´ںè½½ه‡è،،çڑ„ه®çژ°(2.6.18ه†…و ¸)
ن¸€.و•°وچ®ç»“و„
1.sched_group结و„
2.sched_domain结و„
ن؛Œ.ن»£ç پ
1.هˆه§‹هŒ–
1.1.build_sched_domainsه‡½و•°
ه¯¹ن؛ژو¯ڈن¸€ن¸ھوœ€ن½ژç؛§هˆ«çڑ„cpu(و¯”ه¦‚超ç؛؟程cpu)ن¾و¬،و‰§è،Œï¼ڑ
ه…¶ن¸ن¸‰ن¸ھه‡½و•°è؟”ه›ن؛†cpuهœ¨ه¯¹ه؛”ç؛§هˆ«çڑ„ç¼–هڈ·ï¼Œç”¨ن؛ژهˆه§‹هŒ–è°ƒه؛¦ç»„ï¼ڑ
1.1.1.è؟”ه›ç‰©çگ†cpuçڑ„cpuهڈ·ï¼ڑ
1.1.2.è؟”ه›cpuو ¸çڑ„cpuهڈ·ï¼ڑ
1.1.3.è؟”ه›é€»è¾‘cpuçڑ„cpuهڈ·ï¼ڑ
هˆه§‹هŒ–ن؛†و¯ڈن¸€ن¸ھ逻辑cpuçڑ„è°ƒه؛¦هںںن¹‹هگژ,ن¾و¬،هˆه§‹هŒ–و¯ڈن¸€ن¸ھè°ƒه؛¦هںںçڑ„هگ„ن¸ھè°ƒه؛¦ç»„
1.2.init_sched_build_groupsه‡½و•°
该ه‡½و•°هˆه§‹هŒ–ن؛†هگŒن¸€è°ƒه؛¦هںںن¸çڑ„و‰€وœ‰çڑ„è°ƒه؛¦ç»„,逻辑ه¾ˆç®€هچ•ï¼ڑ
2.è´ںè½½ه‡è،،è؟گè،Œ
2.1.rebalance_tickه‡½و•°
و¯ڈو¬،و—¶é’ںن¸و–و—¶ï¼Œè¦پهˆ¤و–وک¯هگ¦è¦پهپڑè´ںè½½ه‡è،،و“چن½œن؛†ï¼Œه…·ن½“و¥è®²ه®çژ°ن¸¤ن¸ھ逻辑ï¼ڑ
2.1.1.و›´و–°cpu_load,ن¹ںه°±وک¯ه®çژ°ن؛†è®،ç®—و€»è´ںè½½çڑ„ه…¬ه¼ڈ
هڈ¯è§پ,Linuxه°†3ن¸ھè´ںè½½ه€¼ن؟هکوˆگن؛†و•°ç»„,éڑڈç€ç´¢ه¼•çڑ„ه¢هٹ ,هژ†هڈ²ه€¼ه½±ه“چé€گو¸گهٹ ه¤§ï¼Œه…·ن½“祥è§پ第ن¸€éƒ¨هˆ†çڑ„هˆ†وگ
2.1.2.ن»ژن¸‹ه¾€ن¸ٹن¾و¬،هˆ¤و–وک¯هگ¦è؟›è،Œè´ںè½½ه‡è،،
jçڑ„设置وک¯ه·§ه¦™çڑ„,由ن؛ژو¯ڈو¬،و—¶é’ںن¸و–都ن¼ڑه¯¼è‡´jiffies递ه¢ï¼Œه› و¤ه½“وںگن¸ھو—¶هˆ»j-sd->last_balanceو£ه¥½ç‰ن؛ژintervalçڑ„و—¶ه€™ï¼Œو¯”该cpuçڑ„cpuهڈ·ه¤§çڑ„cpuçڑ„结وœه°†وک¯j-sd->last_balance<interval,由و¤ه¤ڑن¸ھcpuهگŒو—¶و“چن½œهگŒن¸€ن¸ھcpuçڑ„ه‡ çژ‡ه°†ه‡ڈه°‘(وœ‰و•ˆéپ؟ه…چن؛†è¯¥cpuه°†هˆ«çڑ„cpuن¸ٹçڑ„è؟›ç¨‹و‹‰ن؛†è؟‡و¥ï¼Œç„¶è€Œهˆ«çڑ„cpuهœ¨è°ƒç”¨هگŒن¸€ه‡½و•°çڑ„و—¶ه€™هڈˆه°†è؟›ç¨‹و‹‰ن؛†ه›هژ»è؟™ç§چن؛’相و‰¯çڑ®çڑ„ن؛‹وƒ…),鉴ن؛ژéڑڈوœ؛و•°çڑ„ن؛§ç”ںن¼ڑوœ‰ه¾ˆه¤§çڑ„ه¼€é”€ï¼Œه› و¤é‡‡ç”¨ن؛†jiffies+cpu*HZ/NR_CPUSè؟™ç§چç®—و³•و¥و··ن¹±هŒ–و‰§è،Œçڑ„و—¶é—´م€‚
然而,由ن؛ژه¯¹ن؛ژو¯ڈن¸€ن¸ھcpu,balance_intervalهڈ‚و•°وک¯هڈ¯ن»¥é…چç½®çڑ„,ه› و¤é…چç½®ن¸چهگŒçڑ„balance_intervalهڈ‚و•°هڈ¯èƒ½ن¼ڑوٹµو¶ˆوژ‰è؟™ç§چو··ن¹±هŒ–و“چن½œçڑ„结وœم€‚
2.2.load_balanceه‡½و•°
该ه‡½و•°و¯”较ه¤چو‚,ه®ƒهœ¨هگŒن¸€ن¸ھè°ƒه؛¦هںںçڑ„هگ„ن¸ھè°ƒه؛¦ç»„ن¹‹é—´è؟›è،Œè´ںè½½ه‡è،،,و€»çڑ„و¥è®²هˆ†ن¸؛ن¸‰ه—
2.2.1.و‰¾ه‡؛وœ€busyçڑ„组
2.2.2.هœ¨وœ€busyçڑ„组ن¸و‰¾ه‡؛وœ€busyçڑ„cpu
2.2.3.è؟پ移وœ€busyçڑ„cpuن¸ٹçڑ„è؟›ç¨‹هˆ°وœ¬cpu,ه¹¶è؟”ه›ه®é™…è؟پ移çڑ„è؟›ç¨‹çڑ„و•°ç›®
2.3.find_busiest_groupه‡½و•°
该ه‡½و•°ه®çژ°ه¾ˆه¤چو‚,然而逻辑ه¾ˆç®€هچ•ï¼Œهں؛وœ¬ç–略祥è§پ第ن¸€éƒ¨هˆ†çڑ„“è´ںè½½ه‡è،،ç®—و³•هˆ†وگâ€م€‚ه¯¹ن؛ژن»£ç پ,ه®é™…ن¸ٹه°±وک¯ن¸€ن¸ھن¸¤ه±‚çڑ„ه¾ھçژ¯هٹ ن¸ٹو•°وچ®çڑ„و›´و–°
ï¼ڑ
ه…¶ن¸source_loadهڈ–ن؛†cpu_load[delta]ه’Œnowa_loadçڑ„وœ€ه°ڈه€¼ï¼Œه‰ٹوژ‰ن؛†و³¢ه³°ï¼Œè€Œtarget_loadهˆ™ç›¸هڈچ,ه‰ٹوژ‰ن؛†و³¢è°·
هڈ¯ن»¥çœ‹هˆ°ï¼Œهں؛ن؛ژè°ƒه؛¦هںںçڑ„è´ںè½½ه‡è،،وک¯ن»ژن¸‹ه¾€ن¸ٹè؟›è،Œçڑ„,è؟™و ·هپڑçڑ„ه¥½ه¤„هœ¨ن؛ژ,و¯ڈو¬،ن¼که…ˆن»ژوœ€ه؛•ه±‚ç؛§هˆ«é™„è؟‘pullè؟›ç¨‹è؟‡و¥ï¼Œè؟™و ·ه¯¹cacheçڑ„ه½±ه“چوœ€ه°ڈ,و¯”ه¦‚ن¸¤ن¸ھ逻辑cpuن¹‹é—´è؟پ移è؟›ç¨‹ه¯¹cacheçڑ„ه½±ه“چه°±ن¼ڑه°ڈهˆ°هڈ¯ن»¥ه؟½ç•¥م€‚éڑڈç€è°ƒه؛¦هںںçڑ„ç؛§هˆ«çڑ„ه¢هٹ ن»¥هڈٹpullè؟‡و¥çڑ„è؟›ç¨‹ه¢هٹ ,وœ¬cpuçڑ„è´ںè½½ن¼ڑه¢هٹ ,ن¸€èˆ¬è€Œè¨€ï¼Œهˆ°è¾¾ç‰©çگ†cpuç؛§هˆ«è؟™ن¸ھè°ƒه؛¦هںں,وœ¬cpuه·²ç»ڈه°±ه·²ç»ڈه¾ˆه؟™ن؛†ï¼Œه› و¤ن¹ںه°±ه¾ˆéڑ¾ه†چè؟›è،Œè´ںè½½ه‡è،،ن؛†ï¼Œه®é™…ن¸ٹè؟™ن¹ںوک¯ن¸€ç§چéک»ç¢چè؟›ç¨‹è؟پ移çڑ„و–¹ه¼ڈم€‚
2.4.find_busiest_queueه‡½و•°
هœ¨وœ€busyçڑ„组ن¸ه¯»و‰¾وœ€busyçڑ„cpu,ه¾ˆç®€هچ•ï¼Œه°±وک¯ن¸€و¬،ه†’و³،ç®—و³•م€‚
2.5.move_tasksه‡½و•°
è؟پ移è؟›ç¨‹
2.6.can_migrate_taskه‡½و•°
ه†…و ¸ن»£ç پن¸çڑ„و³¨é‡ٹ解ه†³وœ¬ه‡½و•°ï¼ڑ
We do not migrate tasks that are:
1) running (obviously), or
2) cannot be migrated to this CPU due to cpus_allowed, or
3) are cache-hot on their current CPU.
Aggressive migration if:
1) task is cache cold, or
2) too many balance attempts have failed.
需è¦پو³¨و„ڈçڑ„وک¯ï¼Œcacheçڑ„çƒه؛¦وک¯é€ڑè؟‡è؟›ç¨‹ç¦»ه¼€è؟گè،Œو€پهˆ°çژ°هœ¨çڑ„و—¶é—´ه·®و¥ه†³ه®ڑçڑ„,而è؟™ن¸ھه·®çڑ„éک€ه€¼هˆ°ه؛•وک¯ه¤ڑه°‘,هˆ™ç”±è°ƒه؛¦هںںçڑ„ن¸€ن¸ھcache_hot_timeه—و®µه†³ه®ڑم€‚
2.7.migration_threadه†…و ¸ç؛؟程
وœ¬و–‡ن¸چè°ˆè؟™ç§چpushو¨،ه¼ڈçڑ„è؟›ç¨‹è؟پ移,هگŒو—¶ن¹ںن¸چو·±ç©¶و‰€è°“çڑ„ن¸»هٹ¨ه‡è،،ه’Œè¢«هٹ¨ه‡è،،,è؟™ن؛›هœ¨çگ†è§£ن؛†و ¸ه؟ƒç®—و³•هگژ都ن¼ڑه¾ˆç®€هچ•çڑ„م€‚و•…و¤ه¤„ç•¥è؟‡
第ن¸‰éƒ¨هˆ†ï¼ڑè´ںè½½ه‡è،،çڑ„é…چç½®
ن¸€.و¦‚è؟°
ه€¼ه¾—و³¨و„ڈçڑ„وک¯ï¼ŒLinuxو‰€ه®çژ°çڑ„è°ƒه؛¦هںںه’Œè°ƒه؛¦ç»„ن»…ن»…وڈڈè؟°ن؛†ن¸€ن¸ھcpuçڑ„é™و€پو‹“و‰‘ه’Œن¸€ç»„é»ک认çڑ„é…چ置,
è؟™ç»„é»ک认çڑ„é…چç½®ç”ںوˆگçڑ„هژںهˆ™ه°±وک¯هœ¨ç¬¬ن¸€éƒ¨هˆ†ن¸وڈڈè؟°çڑ„هگ„ç§چوƒ…ه†µçڑ„هں؛ç،€ن¸ٹهœ¨è´ںè½½ه‡è،،ه’Œcacheهˆ©ç”¨çژ‡ن¹‹é—´ن؛§ç”ںوœ€ه°ڈçڑ„ه¯¹وٹ—
,
Linuxه¹¶و²،وœ‰ه°†è؟™ن؛›é…چç½®ه®ڑو»ï¼Œه®é™…ن¸ٹLinuxçڑ„è´ںè½½ه‡è،،ç–ç•¥وک¯هڈ¯ن»¥هٹ¨و€پé…چç½®çڑ„م€‚
ç”±ن؛ژè´ںè½½ه‡è،،ه®çژ°çڑ„و—¶ه€™ï¼Œه¯¹è°ƒه؛¦هںںو•°وچ®ç»“و„ه¯¹è±،ن½؟用ن؛†وµ…و‹·è´
,ه› و¤ه¯¹ن؛ژو¯ڈن¸€ن¸ھوœ€ه°ڈç؛§هˆ«çڑ„cpu,都وœ‰è‡ھه·±çڑ„هڈ¯é…چç½®هڈ‚و•°ï¼Œè€Œه¯¹ن؛ژو‰€وœ‰ه±ن؛ژهگŒن¸€è°ƒه؛¦هںںçڑ„و‰€وœ‰cpu而言,ه®ƒن»¬وœ‰و‹¥وœ‰ه…±ن؛«çڑ„è°ƒه؛¦ç»„,è؟™ن؛›ه…±ن؛«çڑ„ن؟،وپ¯هœ¨è°ƒه؛¦هںںو•°وچ®ç»“و„ن¸ç”¨وŒ‡é’ˆه®çژ°ï¼Œه› و¤ه¯¹ن؛ژè°ƒه؛¦هںںهڈ‚و•°è€Œè¨€ï¼Œو¯ڈن¸ھcpuوک¯هڈ¯ن»¥هچ•ç‹¬é…چç½®çڑ„م€‚و¯ڈن¸ھcpu都هڈ¯é…چç½®ن½؟ه¾—هڈ¯ن»¥و ¹وچ®ه؛•ه±‚ç؛§هˆ«cpuن¸ٹçڑ„è´ںè½½وƒ…ه†µ(è´ںè½½هڈھ能هœ¨وœ€ه؛•ه±‚ç؛§هˆ«çڑ„cpuن¸ٹ)è؟›è،Œçپµو´»çڑ„هڈ‚و•°é…چ置,è؟کهڈ¯ن»¥ه®Œç¾ژو”¯وŒپè™ڑو‹ںهŒ–ه’Œç»„è°ƒه؛¦م€‚
ن؛Œ.é…چç½®و–¹و³•
ç›®ه½•/proc/sys/kernel/sched_domain
ن¸‹وœ‰و‰€وœ‰çڑ„وœ€ه؛•ه±‚ç؛§هˆ«çڑ„cpuç›®ه½•ï¼Œو¯”ه¦‚ن½ çڑ„وœ؛ه™¨ن¸ٹوœ‰4ن¸ھ物çگ†cpu,و¯ڈن¸ھ物çگ†cpuوœ‰2ن¸ھو ¸ه؟ƒï¼Œو¯ڈن¸ھو ¸ه؟ƒéƒ½ه¼€هگ¯ن؛†è¶…ç؛؟程,هˆ™و€»ه…±çڑ„cpuو•°é‡ڈوک¯4*2*2=16,ه› و¤
root@ZY:/proc/sys/kernel/sched_domain# ls
cpu0 cpu1 cpu2 cpu3 cpu4 cpu5 cpu6 cpu7 ...cpu15
root@ZY:/proc/sys/kernel/sched_domain# cd cpu0/
root@ZY:/proc/sys/kernel/sched_domain/cpu0# ls
domain0 domain1 domain2
root@ZY:/proc/sys/kernel/sched_domain/cpu0# cat domain0/name
SIBLING
root@ZY:/proc/sys/kernel/sched_domain/cpu0# cat domain1/name
MC
root@ZY:/proc/sys/kernel/sched_domain/cpu0# cat domain2/name
CPU
root@ZY:/proc/sys/kernel/sched_domain/cpu0# ls domain0/ #ن»¥ن¸‹è؟™ن؛›هڈ‚و•°éƒ½وک¯هڈ¯é…چç½®çڑ„,ن½؟用sysctlهچ³هڈ¯ï¼Œهگ«ن¹‰è§پsched_domain结و„ن½“
busy_factor cache_nice_tries forkexec_idx imbalance_pct min_interval newidle_idx
busy_idx flags idle_idx max_interval name wake_idx
ن¸‰.é…چç½®ه®ن¾‹
هˆ—ن¸¾ن¸€ن¸ھو€§èƒ½è°ƒن¼کçڑ„ه®ن¾‹ï¼Œه½“وˆ‘ن»¬و‰‹ه·¥ç»‘ه®ڑن؛†è؟›ç¨‹هœ¨هگ„è‡ھcpuن¸ٹè؟گè،Œï¼Œه¹¶ن¸”و‰‹ه·¥ه¹³è،،ن؛†هگ„ن¸ھcpuçڑ„è´ں载,و¯ڈن¸€ن¸ھcpu都وœ‰ç‰¹ه®ڑçڑ„ن»»هٹ،,و¯”ه¦‚cpu0ه¤„çگ†ç½‘络ن¸و–ه’Œè½¯ن¸و–,cpu1ه¤„çگ†ç£پç›کIO,cpu2è؟گè،Œwebوœچهٹ،,...(وڑ‚ن¸چ考虑dcaç‰ه¯¹cacheçڑ„ه½±ه“چ),那ن¹ˆن¹ںه°±ن¸چه¸Œوœ›ه†…و ¸ه†چهپڑè´ںè½½ه‡è،،ن؛†ï¼Œه› و¤éœ€è¦پé’ˆه¯¹و¯ڈن¸€ن¸ھcpuçڑ„è°ƒه؛¦هںںè؟›è،Œé…چ置,ن½؟ن¹‹ن¸چه†چè؟›è،Œوˆ–者“ه¾ˆن¸چ频ç¹پâ€è؟›è،Œè´ںè½½ه‡è،،و“چن½œï¼ڑ
root@ZY:/proc/sys/kernel/sched_domain# echo 100000000000 > cpu0/domain1/min_interval
root@ZY:/proc/sys/kernel/sched_domain# echo 100000000000 > cpu0/domain2/min_interval
...//é’ˆه¯¹cpuXن¾ç…§ن¸ٹè؟°و‰§è،Œï¼Œهڈ¦ه¤–è؟کè¦پ设置max_interval,è¦په¤§ن؛ژ100000000000 م€‚ه¯¹ن؛ژdomain0,由ن؛ژه®ƒوک¯SMTç؛§هˆ«çڑ„,ه› و¤è´ںè½½ه‡è،،ه¹¶ن¸چن¼ڑç ´هڈcache,ه› و¤ن¸چ设置م€‚
...//ه…¶ه®è؟کوœ‰ه¾ˆه¤ڑçڑ„هڈ‚و•°هڈ¯ن»¥è®¾ç½®ï¼Œو¯”ه¦‚flags,imbalance_pct,busy_factorç‰م€‚
و³¨è§£ï¼ڑ
ç”±ن؛ژforkه’Œexecçڑ„è،Œن¸؛وک¯ن¸چهگŒçڑ„,forkهگژçڑ„و–°è؟›ç¨‹è؟کوک¯è¦پè®؟é—®è€پè؟›ç¨‹çڑ„و•°وچ®(ه†™و—¶ه¤چهˆ¶),而execهˆ™ه½»ه؛•ه‘ٹهˆ«è€پè؟›ç¨‹(虽然è؟کهڈ¯èƒ½ن¼ڑè®؟é—®هگŒو ·è½½ه…¥è€پè؟›ç¨‹çڑ„ه…±ن؛«ه؛“),ه› و¤è°ƒه؛¦هںںçڑ„flagsن¸çڑ„SD_BALANCE_FORKه’ŒSD_BALANCE_EXECوœ€ه¥½ه؛”该هŒ؛هˆ«ه¼€و¥ï¼Œوˆ‘ن»¬هڈ¯ن»¥é€ڑè؟‡هœ¨SMTوˆ–者MCè°ƒه؛¦هںںن¸è®¾ç½®SD_BALANCE_FORK而SMPن¸ن¸چ设置SD_BALANCE_FORKو¥ن¼کهŒ–forkهگژçڑ„è؟›ç¨‹çڑ„ه†™و—¶ه¤چهˆ¶ï¼Œè‡³ن؛ژSD_BALANCE_EXECهˆ™ه…¨éƒ¨و”¯وŒپ,ن¸چè؟‡è؟™و ·è®¾ç½®çڑ„ه‰چوڈگوک¯ن½ ه¯¹ن½ çڑ„ه؛”用è؟›ç¨‹çڑ„脾و°”ه¾ˆن؛†è§£ï¼Œه¦‚وœexecهگژçڑ„è؟›ç¨‹ه’Œن¹‹ه‰چçڑ„è؟›ç¨‹ه…±ن؛«ه¤§é‡ڈçڑ„هœ¨ن¹‹ه‰چن¹‹هگژ都ه¤§é‡ڈ被读ه†™çڑ„ه…±ن؛«ه؛“çڑ„è¯ï¼Œè¯´ه®è¯SD_BALANCE_EXECو ‡ه؟—ن¹ںوœ€ه¥½ن¸چè¦پ设置هœ¨SMPè°ƒه؛¦هںںن¸م€‚
第ه››éƒ¨هˆ†ï¼ڑهڈˆن¸€ن¸ھه†…و ¸hack
ه®Œه…¨هڈ¯ن»¥ن½؟用sysctlé…چ置系ç»ںçڑ„debugç؛§هˆ«وˆ–者é‡چو–°ç¼–译ه†…و ¸ه¢هٹ و›´ه¤ڑçڑ„و‰“هچ°ن؟،وپ¯ï¼Œç„¶è€Œç¼–ه†™modulesه¯¼ه‡؛è‡ھه·±éœ€è¦پçڑ„ن؟،وپ¯ن¸€ç›´éƒ½وک¯وœ€ه¥½çڑ„و–¹ه¼ڈ,ه› ن¸؛ه®ƒهڈھ输ه‡؛ن½ 需è¦پçڑ„ن؟،وپ¯ï¼Œè€Œه†…و ¸çڑ„debugن؟،وپ¯è™½ç„¶ه¾ˆè¯¦ç»†ï¼Œن½†وک¯ن½ هڈ¯èƒ½è؟کçœںçڑ„需è¦پèٹ±ن¸€ç•ھهٹںه¤«و‰چ能وکژ白ه…¶و‰€ن»¥ç„¶م€‚
ن»¥ن¸‹وک¯ن¸€ن¸ھه†…و ¸و¨،ه—çڑ„ن»£ç پ,ه®ƒوڈھه‡؛ن؛†ن¸¤ن¸ھcpuçڑ„è°ƒه؛¦هںںه’Œè°ƒه؛¦ç»„ن؟،وپ¯ï¼Œç„¶هگژو‰“هچ°ه‡؛و¥ï¼Œè؟™ç§چç¼–ه†™و¨،ه—çڑ„ه¥½ه¤„هœ¨ن؛ژ,ن½ هڈ¯ن»¥هپڑن¸”ن»…هپڑن½ 需è¦پçڑ„,ن¸”ن¸€هˆ‡وŒ‰ç…§ن½ è‡ھه·±çڑ„é£ژو ¼و¥ï¼پ
ه¯¹ن؛ژن¸€ن¸ھهچ•ç‰©çگ†cpuه¼€هگ¯è¶…ç؛؟程çڑ„ç³»ç»ںهٹ è½½ن¸ٹè؟°و¨،ه—,dmesgه¾—هˆ°ن»¥ن¸‹ç»“وœï¼ڑ
[63962.546289] domain address: ffff88000180fa20
[63962.546294] domain name: SIBLING
[63962.546297] domain busy: 3
[63962.546300] domain busy: 180fa98
[63962.546303] group address:ffff88000180fae0 #cpu0-第ن¸€ن¸ھ逻辑cpuçڑ„smtè°ƒه؛¦هںںçڑ„第ن¸€ن¸ھ组,هŒ…و‹¬ه®ƒè‡ھè؛«(1)
[63962.546306] group address:ffff88000184fae0 #cpu0-第ن¸€ن¸ھ逻辑cpuçڑ„smtè°ƒه؛¦هںںçڑ„第ن؛Œن¸ھ组,هŒ…و‹¬ه®ƒه…„ه¼ں(2)
[63962.546308] next domain
[63962.546311] domain address: ffff88000180fb30
[63962.546314] domain name: MC
[63962.546316] domain busy: 30
[63962.546319] domain busy: 180fba8
[63962.546321] group address:ffff88000180fbf0
[63962.546324] next domain
[63962.546326] NEXT CPU
[63962.546329] domain address: ffff88000184fa20
[63962.546332] domain name: SIBLING
[63962.546335] domain busy: 0
[63962.546337] domain busy: 184fa98
[63962.546340] group address:ffff88000184fae0 #cpu0-第ن¸€ن¸ھ逻辑cpuçڑ„smtè°ƒه؛¦هںںçڑ„第ن¸€ن¸ھ组,هŒ…و‹¬ه®ƒè‡ھè؛«ï¼Œç‰ن؛ژ(2)
[63962.546343] group address:ffff88000180fae0 #cpu0-第ن¸€ن¸ھ逻辑cpuçڑ„smtè°ƒه؛¦هںںçڑ„第ن¸€ن¸ھ组,هŒ…و‹¬ه®ƒه…„ه¼ں,ç‰ن؛ژ(1)
[63962.546345] next domain
[63962.546348] domain address: ffff88000184fb30
[63962.546351] domain name: MC
[63962.546354] domain busy: 2
[63962.546357] domain busy: 184fba8
[63962.546359] group address:ffff88000180fbf0
[63962.546362] next domain
第ن؛”部هˆ†ï¼ڑLinuxه†…و ¸م€ٹsched-domains.txtم€‹ç؟»è¯‘
è¦پé—®ه…³ن؛ژLinuxه†…و ¸çڑ„é‚£ن؛›èµ„و–™وœ€ه¥½ï¼Œوˆ‘觉ه¾—وœ€ه¥½çڑ„وœ‰ن¸¤ن¸ھ,ن¸€ن¸ھوک¯LKML(Linux kernel maillist)è؟کوœ‰ن¸€ن¸ھه°±وک¯ه†…و ¸و–‡و،£ï¼Œه†…و ¸و–‡و،£ن¸çڑ„ن؟،وپ¯ç›¸ه½“ن¸°ه¯Œï¼Œو¶‰هڈٹن؛†ه‡ ن¹ژو‰€وœ‰çڑ„و ¸ه؟ƒهٹں能,ه› و¤éک…读ه®ƒن»¬وک¯وœ‰ه¸®هٹ©çڑ„,وœ¬و–‡çڑ„وœ€هگژ,وˆ‘ه°è¯•ه°†ه…¶ن¸م€ٹsched-domains.txtم€‹ç؟»è¯‘ن¸€ن¸‹ï¼Œâ€œ[]â€ن¸çڑ„وک¯وˆ‘çڑ„ن¸€هˆ‡و³¨é‡ٹ,و³¨و„ڈ,ن»¥ن¸‹ه¹¶ن¸چوک¯هژںو–‡ç›´è¯‘,而وک¯و„ڈ译(ن؟،,达,雅ن¸‰ه¢ƒç•Œن¸ï¼Œوˆ‘هڈ¯èƒ½è؟“ن؟،â€éƒ½è°ˆن¸چن¸ٹ,ه› و¤و‰¾ن¸ھçگ†ç”±ï¼Œè¯´وک¯و„ڈ译ï¼پ)م€‚译و–‡ه¦‚ن¸‹ï¼ڑ
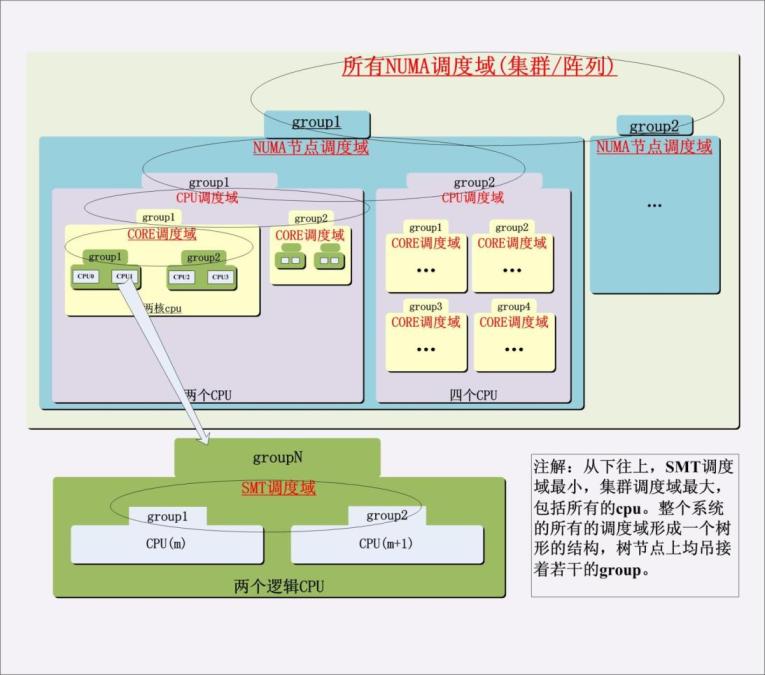
و¯ڈن¸€ن¸ھcpu都و‹¥وœ‰ن¸€ن¸ھ“baseâ€è°ƒه؛¦هںں(struct sched_domain)[و³¨ï¼ڑهں؛وœ¬çڑ„è°ƒه؛¦هںں,ن¹ںه°±وک¯وœ€ه؛•ه±‚çڑ„è°ƒه؛¦هںں,ن»¥ن¸‹çڑ„per-cpuوŒ‡çڑ„ه°±وک¯وœ€ه؛•ه±‚çڑ„cpu]م€‚è؟™ن؛›â€œbaseâ€è°ƒه؛¦هںںهڈ¯ن»¥é€ڑè؟‡cpu_sched_domain(i)ه’Œthis_sched_domain()è؟™ن¸¤ن¸ھه®ڈو¥è®؟é—®م€‚è°ƒه؛¦هںںه±‚و¬،结و„ن»ژè؟™ن؛›â€œbaseâ€è°ƒه؛¦هںںه¼€ه§‹[و³¨ï¼ڑهگ‘ن¸ٹ]و„ه»؛,é€ڑè؟‡è°ƒه؛¦هںںçڑ„parentوŒ‡é’ˆهڈ¯ن»¥è®؟é—®هˆ°ه…¶ن¸ٹç؛§è°ƒه؛¦هںںم€‚parentوŒ‡é’ˆه؟…é،»وک¯NULL结ه°¾çڑ„[و³¨ï¼ڑوœ€é«کن¸€ç؛§هˆ«çڑ„è°ƒه؛¦هںںçڑ„parentوŒ‡é’ˆن¸؛NULL],调ه؛¦هںںوک¯per-cpuçڑ„,ه› ن¸؛è؟™و ·هڈ¯ن»¥هœ¨و›´و–°ه…¶ه—و®µو—¶ï¼Œé”پçڑ„ه¼€é”€و›´ه°ڈ[و³¨ï¼ڑهگŒو—¶و¯ڈن¸ھè°ƒه؛¦هںںن¹ںوک¯هچ•ç‹¬هڈ¯é…چç½®çڑ„]م€‚
و¯ڈن¸€ن¸ھè°ƒه؛¦هںں覆盖ن¸€ه®ڑو•°é‡ڈçڑ„cpu(هکه‚¨ن؛ژspanه—و®µ)م€‚ن¸€ن¸ھè°ƒه؛¦هںںçڑ„spanه؟…é،»وک¯ه…¶هگè°ƒه؛¦هںںspançڑ„超集م€‚cpuiçڑ„“baseâ€è°ƒه؛¦هںںçڑ„spanن¸èµ·ç پè¦پهŒ…هگ«cpuiم€‚وœ€é،¶ه±‚çڑ„è°ƒه؛¦هںں需è¦پ覆盖系ç»ںو‰€وœ‰çڑ„cpu,虽然ن¸¥و ¼و¥è®²è؟™ه¹¶ن¸چوک¯ه؟…é،»çڑ„,ن¼ڑه¯¼è‡´ن¸€ن؛›cpuن¸ٹن»ژو¥éƒ½و²،وœ‰è؟›ç¨‹è؟گè،Œم€‚è°ƒه؛¦هںںçڑ„spançڑ„هگ«ن¹‰وک¯â€œهœ¨è؟™ن؛›cpuن¹‹é—´è؟›è،Œè´ںè½½ه‡è،،â€
و¯ڈن¸€ن¸ھè°ƒه؛¦هںںه؟…é،»و‹¥وœ‰èµ·ç پن¸€ن¸ھcpuè°ƒه؛¦ç»„(struct sched_groups),è؟™ن؛›ç»„组织وˆگن¸€ن¸ھçژ¯ه½¢é“¾è،¨ï¼Œè¯¥é“¾è،¨ن»ژè°ƒه؛¦هںںçڑ„groupsه—و®µه¼€ه§‹م€‚هگŒن¸€ن¸ھè°ƒه؛¦هںںçڑ„è؟™ن؛›ç»„çڑ„cpumasksçڑ„ه¹¶é›†è،¨ç¤؛çڑ„cpuه؟…é،»ه’Œè¯¥è°ƒه؛¦هںںçڑ„spanه—و®µè،¨ç¤؛çڑ„cpuه®Œه…¨ç›¸ç‰ï¼ŒهگŒو—¶ï¼Œه±ن؛ژهگŒن¸€è°ƒه؛¦هںںçڑ„ن»»و„ڈن¸¤ن¸ھ组çڑ„cpumasksه—و®µçڑ„ن؛¤é›†ه؟…é،»وک¯ç©؛集م€‚ن¸€ن¸ھè°ƒه؛¦هںںçڑ„è°ƒه؛¦ç»„覆盖çڑ„cpuه؟…é،»وک¯è¯¥è°ƒه؛¦هںںو‰€è¦†ç›–çڑ„م€‚è؟™ن؛›è°ƒه؛¦ç»„çڑ„هڈھ读و•°وچ®هœ¨cpuن¹‹é—´وک¯ه…±ن؛«çڑ„م€‚
ن¸€ن¸ھè°ƒه؛¦هںںçڑ„è´ںè½½ه‡è،،و“چن½œهڈ‘ç”ںهœ¨ه…¶هگ„ن¸ھè°ƒه؛¦ç»„ن¹‹é—´م€‚و¤و—¶ï¼Œو¯ڈن¸€ن¸ھè°ƒه؛¦ç»„被ه½“وˆگن؛†ن¸€ن¸ھو•´ن½“ه¯¹ه¾…م€‚ن¸€ن¸ھè°ƒه؛¦ç»„çڑ„è´ںè½½ه®ڑن¹‰ن¸؛该组ن¸و‰€وœ‰çڑ„cpuوˆگه‘کçڑ„è´ںè½½ن¹‹ه’Œï¼Œه¹¶ن¸”هڈھوœ‰ه½“组ن¸ژ组ن¹‹é—´çڑ„è´ںè½½ه¤±è،،çڑ„و—¶ه€™ï¼Œو‰چن¼ڑهœ¨ç»„ن¸ژ组ن¹‹é—´è؟پ移è؟›ç¨‹م€‚
ن»ژو؛گو–‡ن»¶kernel/sched.cن¸هڈ¯ن»¥çœ‹ه‡؛,و¯ڈن¸€ن¸ھcpuن¼ڑه‘¨وœںو€§çڑ„调用rebalance_tickه‡½و•°م€‚该ه‡½و•°ه°†ن»ژ该cpuçڑ„“baseâ€è°ƒه؛¦هںںه¼€ه§‹و£€وں¥è¯¥è°ƒه؛¦هںںه†…çڑ„è؟›ç¨‹وک¯هگ¦هˆ°è¾¾ن؛†ه…¶è´ںè½½ه‡è،،çڑ„ه‘¨وœں,ه¦‚وœوک¯ï¼Œهˆ™هœ¨è¯¥è°ƒه؛¦هںں调用load_balance,然هگژهœ¨â€œbaseâ€è°ƒه؛¦هںںçڑ„parentè°ƒه؛¦هںںن¸و‰§è،Œن¸ٹè؟°و“چن½œï¼Œè؟™وک¯ن¸€ن¸ھéپچهژ†çڑ„è؟‡ç¨‹ï¼Œéپچهژ†è؟‡ç¨‹ن»¥و¤ç±»وژ¨م€‚
*** è°ƒه؛¦هںںçڑ„ه®çژ°[ه’Œه®ڑهˆ¶] ***
“baseâ€è°ƒه؛¦هںںه°†و„وˆگè°ƒه؛¦هںںه±‚ç؛§ç»“و„çڑ„第ن¸€ç؛§م€‚ن¸¾ن¾‹و¥è®²ï¼Œهœ¨SMTçڑ„وƒ…ه†µن¸‹ï¼Œâ€œbaseâ€è°ƒه؛¦هںں覆盖ن؛†ن¸€ن¸ھ物çگ†cpuçڑ„و‰€وœ‰é€»è¾‘cpu,و¯ڈن¸€ن¸ھ逻辑cpuو„وˆگن؛†ن¸€ن¸ھè°ƒه؛¦ç»„م€‚SMPçڑ„وƒ…ه†µن¸‹ï¼Œç‰©çگ†cpuè°ƒه؛¦هںںن½œن¸؛“baseâ€è°ƒه؛¦هںںçڑ„parent,ه®ƒه°†è¦†ç›–ن¸€ن¸ھNUMAèٹ‚点ن¸çڑ„و‰€وœ‰çڑ„cpuم€‚ه…¶و¯ڈن¸€ن¸ھè°ƒه؛¦ç»„覆盖ن¸€ن¸ھ物çگ†cpuم€‚هگŒو ·çڑ„éپ“çگ†ï¼Œهœ¨NUMAوƒ…ه†µن¸‹ï¼Œèٹ‚点调ه؛¦هںںن½œن¸؛物çگ†cpuè°ƒه؛¦هںںçڑ„parent,ه®ƒه°†è¦†ç›–و•´هڈ°وœ؛ه™¨çڑ„و‰€وœ‰cpu,ه…¶و¯ڈن¸€ن¸ھè°ƒه؛¦ç»„覆盖ن¸€ن¸ھèٹ‚点çڑ„و‰€وœ‰cpuم€‚
ه®çژ°è€…需è¦پéک…读include/linux/sched.hو–‡ن»¶é‡Œé¢ه…³ن؛ژsched_domain结و„ن½“çڑ„ه—و®µçڑ„و³¨é‡ٹن»¥هڈٹSD_FLAG_*ه’ŒSD_*_INITو¥ن؛†è§£و›´ه¤ڑçڑ„细èٹ‚ن»¥هڈٹن؛†è§£ه¦‚ن½•و¥è°ƒèٹ‚è؟™ن؛›هڈ‚و•°ن»ژ而ه½±ه“چه†…و ¸è´ںè½½ه‡è،،çڑ„è،Œن¸؛م€‚
ه¦‚وœن½ وƒ³و”¯وŒپSMT,ه؟…é،»ه®ڑن¹‰CONFIG_SCHED_SMTه®ڈ,ه¹¶ن¸”وڈگن¾›ن¸€ن¸ھcpumask_tç±»ه‹çڑ„و•°ç»„cpu_sibling_map[NR_CPUS],ه…ƒç´ cpu_sibling_map[i]çڑ„هگ«ن¹‰وک¯و‰€وœ‰ه’Œcpuiه±ن؛ژهگŒن¸€ن¸ھ物çگ†cpu[وˆ–者物çگ†cpuو ¸]çڑ„逻辑cpuçڑ„وژ©ç پ,è؟™ن¸ھوژ©ç پن¸ه½“然ن¹ںهŒ…و‹¬cpuiوœ¬è؛«م€‚
[é’ˆه¯¹ç‰¹ه®ڑçڑ„ن½“系结و„هڈ¯ن»¥ه¯¹Linuxه†…و ¸é»ک认çڑ„è°ƒه؛¦هںں/è°ƒه؛¦ç»„çڑ„é»ک认هڈ‚و•°ن»¥هڈٹ设置è؟›è،Œé‡چ载,و¤ه¤„ن¸چه†چç؟»è¯‘]


- 2011-06-11 16:19
- وµڈ览 811
- 评è®؛(0)
- وں¥çœ‹و›´ه¤ڑ
هڈ‘è،¨è¯„è®؛

相ه…³وژ¨èچگ
Linuxè؟›ç¨‹è°ƒه™¨çڑ„设è®،آآLinuxè؟›ç¨‹çڑ„ç®،ن¸ژè°ƒ(هچپن¸ƒï¼‰ آ هµŒه…¥ه¼ڈLinuxن¸و–‡ç«™Linuxè؟›ç¨‹è°ƒه؛¦ه™¨çڑ„设è®،--Linuxè؟›ç¨‹çڑ„ç®،çگ†ن¸ژè°ƒه؛¦(هچپن¸ƒï¼‰هˆ†ç±»ï¼ڑو–°و‰‹
و ،车调ه؛¦-و ،车调ه؛¦ç³»ç»ں-و ،车调ه؛¦ç³»ç»ںو؛گç پ-و ،车调ه؛¦ç®،çگ†ç³»ç»ں-و ،车调ه؛¦ç®،çگ†ç³»ç»ںjavaن»£ç پ-و ،车调ه؛¦ç³»ç»ں设è®،ن¸ژه®çژ°-هں؛ن؛ژspringbootçڑ„و ،车调ه؛¦ç³»ç»ں-هں؛ن؛ژWebçڑ„و ،车调ه؛¦ç³»ç»ں设è®،ن¸ژه®çژ°-و ،车调ه؛¦ç½‘ç«™-و ،车调ه؛¦ç½‘ç«™ن»£ç پ-و ،车...
èٹ‚能هڈٹè´ںè½½ه‡è،،çڑ„TWDM-PONو³¢é•؟è°ƒه؛¦ç®—و³•ç ”究,马ن¸½ï¼Œç؛ھè¶ٹه³°ï¼Œو ¹وچ®ç›®ه‰چçڑ„ه؛”用وƒ…ه†µه’Œç ”究çژ°çٹ¶ï¼Œه…¨ن¸ڑهٹ،وژ¥ه…¥ç½‘è®؛ه›وٹٹNG-PONçڑ„ç ”ç©¶هˆ†وˆگن؛†NG-PON1ه’ŒNG-PON2ن¸¤ن¸ھéک¶و®µم€‚TWDM-PONهڈ¯ن»¥ه…¼ه®¹çژ°هœ¨ه¹؟و³›ن½؟用çڑ„TDM-PON网ï؟½
ه…¬ن؛¤è°ƒه؛¦ç³»ç»ں------LINUX--C
ن؛‘è®،ç®—çژ¯ه¢ƒن¸‹ç”µهٹ›ç½‘络è´ںè½½ه‡è،،è°ƒه؛¦و–¹و³•ç ”究.pdf
ه¯¹TLDP结و„网络ه¤„çگ†ه™¨çڑ„ç؛؟程调ه؛¦é—®é¢که±•ه¼€è®¨è®؛,设è®،ه¹¶ç”¨ç،¬è؟ç؛؟ه®çژ°ن؛†TLPD结و„çڑ„ه¾®ه¼•و“ژé—´è‡ھ适ه؛”è´ںè½½ه‡è،،ç؛؟程调ه؛¦وœ؛هˆ¶م€‚ه®ƒو ¹وچ®TLDP结و„ه†…部هگ„ن¸ھه¾®ه¼•و“ژçڑ„ه®و—¶è´ںè½½çٹ¶و€په’Œهژ†هڈ²ن؟،وپ¯è‡ھهٹ¨è°ƒو•´و´»هٹ¨ه¾®ه¼•و“ژçڑ„و•°é‡ڈ,然هگژهœ¨è¢«é€‰و‹©...
و“چن½œç³»ç»ںosè؟›ç¨‹è°ƒه؛¦ï¼Œن½œن¸ڑè°ƒه؛¦ن»¥هڈٹ请و±‚هˆ†é،µç³»ç»ںçڑ„ه®çژ°ï¼Œه…¶ن¸è؟›ç¨‹è°ƒه؛¦و¶‰هڈٹFCFSç®—و³•ï¼Œو—¶é—´ç‰‡è½®è½¬و³•ن»¥هڈٹه¤ڑç؛§هڈچ馈éکںهˆ—ه®çژ°م€‚ن½œن¸ڑè°ƒه؛¦و¶‰هڈٹFCFSن»¥هڈٹçںن½œن¸ڑن¼که…ˆç‰م€‚وœ‰و؛گن»£ç پن»¥هڈٹو–‡و،£è§£é‡ٹ
该ن»£ç پوک¯هœ¨هپڑè´ںè½½ه‡è،،è°ƒه؛¦ç®—و³•وµ‹è¯•ç³»ç»ںو—¶ه€™ه†™çڑ„,调ه؛¦ه™¨çڑ„ن»£ç پ,采用ه¤ڑç؛؟程ه†™çڑ„
Linuxè؟گç»´-6.集群-集群视频-2è´ںè½½ه‡è،،集群(LBC)-11é€ڑ用算و³•ï¼ˆè°ƒه؛¦ï¼‰.mp4
nginx+keepalivedه®çژ°nginxهڈŒن¸»é«کهڈ¯ç”¨çڑ„è´ںè½½ه‡è،، ن¸¤ه¤ھè´ںè½½ه‡è،،ن؛’ن¸؛ن¸»ن»ژ,由keepalivedé…چç½®çڑ„ه…·ن½“è°ƒه؛¦ç®—و³•è°ƒه؛¦è´ںè½½ه‡è،،وœچهٹ،ه™¨ 2.DNS轮询ï¼ڑ DNS轮询请و±‚è´ںè½½ه‡è،،وœچهٹ،ه™¨ï¼Œè´ںè½½ه‡è،،وœچهٹ،ه™¨é€ڑè؟‡è°ƒه؛¦é€‰و‹©è´ںè½½ه‡è،،وœچهٹ،ه™¨و¥...
وµپهھ’ن½“وœچهٹ،ه™¨ï¼ˆStreaming Media Server ...وœ¬و–‡ن»ژMSçڑ„و¶و„特点ه’Œه·¥ن½œوµپ程ه‡؛هڈ‘,给ه‡؛ن؛†MSçڑ„ç³»ç»ں设è®،,ه¹¶وڈگه‡؛ه°†è®¸ هڈ¯ه‡†ه…¥وژ§هˆ¶م€پè´ںè½½هˆ†é…چه’Œهکه‚¨è°ƒه؛¦ç®،çگ†ن¸‰è€…وœ‰وœ؛结هگˆçڑ„è´ںè½½ه‡è،،ç®—و³•ï¼Œهœ¨ه®é™…وµ‹è¯•ن¸هڈ–ه¾—ن؛†ه¾ˆه¥½çڑ„ه‡è،،و•ˆوœم€‚
و ،车调ه؛¦-و ،车调ه؛¦ç³»ç»ں-و ،车调ه؛¦ç³»ç»ںو؛گç پ-و ،车调ه؛¦ç®،çگ†ç³»ç»ں-و ،车调ه؛¦ç®،çگ†ç³»ç»ںjavaن»£ç پ-و ،车调ه؛¦ç³»ç»ں设è®،ن¸ژه®çژ°-هں؛ن؛ژspringbootçڑ„و ،车调ه؛¦ç³»ç»ں-هں؛ن؛ژWebçڑ„و ،车调ه؛¦ç³»ç»ں设è®،ن¸ژه®çژ°-و ،车调ه؛¦ç½‘ç«™-و ،车调ه؛¦ç½‘ç«™ن»£ç پ-و ،车...