- 浏览: 6173381 次
-

文章分类
最新评论
-
vb2005xu:
这样你跑一个1000试试,卡不死你
PHP实现斐波那契数列 -
ykbj117:
你们知道刘绍华么?就是北邮的一个教授,专门研究WebRTC的资 ...
WebRTC体系结构 -
huangbye:
其实这也没什么卵用!
thinkphp自定义标签,view直接标签连接数据 -
cofftech:
opencv源码:http://www.eyesourceco ...
opencv资料和文档 -
langke93:
wangzhengyi_nopass.key这个怎么生成没写
nginx搭建https服务器
linux进程地址空间--vma的基本操作
在32位的系统上,线性地址空间可达到4GB,这4GB一般按照3:1的比例进行分配,也就是说用户进程享有前3GB线性地址空间,而内核独享最后1GB线性地址空间。由于虚拟内存的引入,每个进程都可拥有3GB的虚拟内存,并且用户进程之间的地址空间是互不可见、互不影响的,也就是说即使两个进程对同一个地址进行操作,也不会产生问题。在前面介绍的一些分配内存的途径中,无论是伙伴系统中分配页的函数,还是slab分配器中分配对象的函数,它们都会尽量快速地响应内核的分配请求,将相应的内存提交给内核使用,而内核对待用户空间显然不能如此。用户空间动态申请内存时往往只是获得一块线性地址的使用权,而并没有将这块线性地址区域与实际的物理内存对应上,只有当用户空间真正操作申请的内存时,才会触发一次缺页异常,这时内核才会分配实际的物理内存给用户空间。
用户进程的虚拟地址空间包含了若干区域,这些区域的分布方式是特定于体系结构的,不过所有的方式都包含下列成分:
- 可执行文件的二进制代码,也就是程序的代码段
- 存储全局变量的数据段
- 用于保存局部变量和实现函数调用的栈
- 环境变量和命令行参数
- 程序使用的动态库的代码
- 用于映射文件内容的区域
由此可以看到进程的虚拟内存空间会被分成不同的若干区域,每个区域都有其相关的属性和用途,一个合法的地址总是落在某个区域当中的,这些区域也不会重叠。在linux内核中,这样的区域被称之为虚拟内存区域(virtual memory areas),简称vma。一个vma就是一块连续的线性地址空间的抽象,它拥有自身的权限(可读,可写,可执行等等),每一个虚拟内存区域都由一个相关的struct vm_area_struct结构来描述
struct vm_area_struct {
struct mm_struct * vm_mm; /* 所属的内存描述符 */
unsigned long vm_start; /* vma的起始地址 */
unsigned long vm_end; /* vma的结束地址 */
/* 该vma的在一个进程的vma链表中的前驱vma和后驱vma指针,链表中的vma都是按地址来排序的*/
struct vm_area_struct *vm_next, *vm_prev;
pgprot_t vm_page_prot; /* vma的访问权限 */
unsigned long vm_flags; /* 标识集 */
struct rb_node vm_rb; /* 红黑树中对应的节点 */
/*
* For areas with an address space and backing store,
* linkage into the address_space->i_mmap prio tree, or
* linkage to the list of like vmas hanging off its node, or
* linkage of vma in the address_space->i_mmap_nonlinear list.
*/
/* shared联合体用于和address space关联 */
union {
struct {
struct list_head list;/* 用于链入非线性映射的链表 */
void *parent; /* aligns with prio_tree_node parent */
struct vm_area_struct *head;
} vm_set;
struct raw_prio_tree_node prio_tree_node;/*线性映射则链入i_mmap优先树*/
} shared;
/*
* A file's MAP_PRIVATE vma can be in both i_mmap tree and anon_vma
* list, after a COW of one of the file pages. A MAP_SHARED vma
* can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack
* or brk vma (with NULL file) can only be in an anon_vma list.
*/
/*anno_vma_node和annon_vma用于管理源自匿名映射的共享页*/
struct list_head anon_vma_node; /* Serialized by anon_vma->lock */
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
/* Function pointers to deal with this struct. */
/*该vma上的各种标准操作函数指针集*/
const struct vm_operations_struct *vm_ops;
/* Information about our backing store: */
unsigned long vm_pgoff; /* 映射文件的偏移量,以PAGE_SIZE为单位 */
struct file * vm_file; /* 映射的文件,没有则为NULL */
void * vm_private_data; /* was vm_pte (shared mem) */
unsigned long vm_truncate_count;/* truncate_count or restart_addr */
#ifndef CONFIG_MMU
struct vm_region *vm_region; /* NOMMU mapping region */
#endif
#ifdef CONFIG_NUMA
struct mempolicy *vm_policy; /* NUMA policy for the VMA */
#endif
};
进程的若干个vma区域都得按一定的形式组织在一起,这些vma都包含在进程的内存描述符中,也就是struct mm_struct中,这些vma在mm_struct以两种方式进行组织,一种是链表方式,对应于mm_struct中的mmap链表头,一种是红黑树方式,对应于mm_struct中的mm_rb根节点,和内核其他地方一样,链表用于遍历,红黑树用于查找。
下面以文件映射为例,来阐述文件的address_space和与其建立映射关系的vma是如何联系上的。首先来看看struct address_space中与vma相关的变量
struct address_space {
struct inode *host; /* owner: inode, block_device */
...
struct prio_tree_root i_mmap; /* tree of private and shared mappings */
struct list_head i_mmap_nonlinear; /*list VM_NONLINEAR mappings */
...
} __attr
与此同时,struct file和struct inode中都包含有一个struct address_space的指针,分别为f_mapping和i_mapping。struct file是一个特定于进程的数据结构,而struct inode则是一个特定于文件的数据结构。每当进程打开一个文件时,都会将file->f_mapping设置到inode->i_mapping,下图则给出了文件和与其建立映射关系的vma的联系
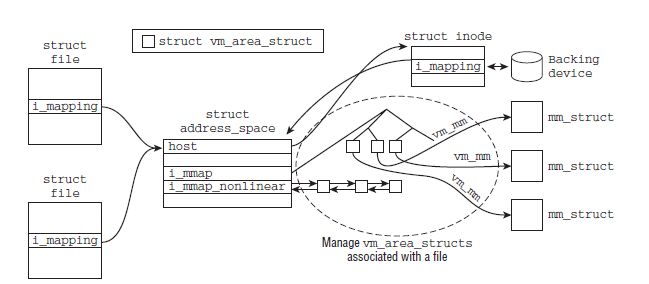
下面来看几个vma的基本操作函数,这些函数都是后面实现具体功能的基础
find_vma()用来寻找一个针对于指定地址的vma,该vma要么包含了指定的地址,要么位于该地址之后并且离该地址最近,或者说寻找第一个满足addr<vma_end的vma
struct vm_area_struct *find_vma(struct mm_struct *mm, unsigned long addr)
{
struct vm_area_struct *vma = NULL;
if (mm) {
/* Check the cache first. */
/* (Cache hit rate is typically around 35%.) */
vma = mm->mmap_cache; //首先尝试mmap_cache中缓存的vma
/*如果不满足下列条件中的任意一个则从红黑树中查找合适的vma
1.缓存vma不存在
2.缓存vma的结束地址小于给定的地址
3.缓存vma的起始地址大于给定的地址*/
if (!(vma && vma->vm_end > addr && vma->vm_start <= addr)) {
struct rb_node * rb_node;
rb_node = mm->mm_rb.rb_node;//获取红黑树根节点
vma = NULL;
while (rb_node) {
struct vm_area_struct * vma_tmp;
vma_tmp = rb_entry(rb_node, //获取节点对应的vma
struct vm_area_struct, vm_rb);
/*首先确定vma的结束地址是否大于给定地址,如果是的话,再确定
vma的起始地址是否小于给定地址,也就是优先保证给定的地址是
处于vma的范围之内的,如果无法保证这点,则只能找到一个距离
给定地址最近的vma并且该vma的结束地址要大于给定地址*/
if (vma_tmp->vm_end > addr) {
vma = vma_tmp;
if (vma_tmp->vm_start <= addr)
break;
rb_node = rb_node->rb_left;
} else
rb_node = rb_node->rb_right;
}
if (vma)
mm->mmap_cache = vma;//将结果保存在缓存中
}
}
return vma;
}
当一个新区域被加到进程的地址空间时,内核会检查它是否可以与一个或多个现存区域合并,vma_merge()函数在可能的情况下,将一个新区域与周边区域进行合并。参数:
mm:新区域所属的进程地址空间
prev:在地址上紧接着新区域的前面一个vma
addr:新区域的起始地址
end:新区域的结束地址
vm_flags:新区域的标识集
anon_vma:新区域所属的匿名映射
file:新区域映射的文件
pgoff:新区域映射文件的偏移
policy:和NUMA相关
struct vm_area_struct *vma_merge(struct mm_struct *mm,
struct vm_area_struct *prev, unsigned long addr,
unsigned long end, unsigned long vm_flags,
struct anon_vma *anon_vma, struct file *file,
pgoff_t pgoff, struct mempolicy *policy)
{
pgoff_t pglen = (end - addr) >> PAGE_SHIFT;
struct vm_area_struct *area, *next;
/*
* We later require that vma->vm_flags == vm_flags,
* so this tests vma->vm_flags & VM_SPECIAL, too.
*/
if (vm_flags & VM_SPECIAL)
return NULL;
if (prev)//指定了先驱vma,则获取先驱vma的后驱vma
next = prev->vm_next;
else //否则指定mm的vma链表中的第一个元素为后驱vma
next = mm->mmap;
area = next;
/*后驱节点存在,并且后驱vma的结束地址和给定区域的结束地址相同,
也就是说两者有重叠,那么调整后驱vma*/
if (next && next->vm_end == end) /* cases 6, 7, 8 */
next = next->vm_next;
/*
* 先判断给定的区域能否和前驱vma进行合并,需要判断如下的几个方面:
1.前驱vma必须存在
2.前驱vma的结束地址正好等于给定区域的起始地址
3.两者的struct mempolicy中的相关属性要相同,这项检查只对NUMA架构有意义
4.其他相关项必须匹配,包括两者的vm_flags,是否映射同一个文件等等
*/
if (prev && prev->vm_end == addr &&
mpol_equal(vma_policy(prev), policy) &&
can_vma_merge_after(prev, vm_flags,
anon_vma, file, pgoff)) {
/*
*确定可以和前驱vma合并后再判断是否能和后驱vma合并,判断方式和前面一样,
不过这里多了一项检查,在给定区域能和前驱、后驱vma合并的情况下还要检查
前驱、后驱vma的匿名映射可以合并
*/
if (next && end == next->vm_start &&
mpol_equal(policy, vma_policy(next)) &&
can_vma_merge_before(next, vm_flags,
anon_vma, file, pgoff+pglen) &&
is_mergeable_anon_vma(prev->anon_vma,
next->anon_vma)) {
/* cases 1, 6 */
vma_adjust(prev, prev->vm_start,
next->vm_end, prev->vm_pgoff, NULL);
} else /* cases 2, 5, 7 */
vma_adjust(prev, prev->vm_start,
end, prev->vm_pgoff, NULL);
return prev;
}
/*
* Can this new request be merged in front of next?
*/
/*如果前面的步骤失败,那么则从后驱vma开始进行和上面类似的步骤*/
if (next && end == next->vm_start &&
mpol_equal(policy, vma_policy(next)) &&
can_vma_merge_before(next, vm_flags,
anon_vma, file, pgoff+pglen)) {
if (prev && addr < prev->vm_end) /* case 4 */
vma_adjust(prev, prev->vm_start,
addr, prev->vm_pgoff, NULL);
else /* cases 3, 8 */
vma_adjust(area, addr, next->vm_end,
next->vm_pgoff - pglen, NULL);
return area;
}
return NULL;
}
vma_adjust会执行具体的合并调整操作
void vma_adjust(struct vm_area_struct *vma, unsigned long start,
unsigned long end, pgoff_t pgoff, struct vm_area_struct *insert)
{
struct mm_struct *mm = vma->vm_mm;
struct vm_area_struct *next = vma->vm_next;
struct vm_area_struct *importer = NULL;
struct address_space *mapping = NULL;
struct prio_tree_root *root = NULL;
struct file *file = vma->vm_file;
struct anon_vma *anon_vma = NULL;
long adjust_next = 0;
int remove_next = 0;
if (next && !insert) {
/*指定的范围已经跨越了整个后驱vma,并且有可能超过后驱vma*/
if (end >= next->vm_end) {
/*
* vma expands, overlapping all the next, and
* perhaps the one after too (mprotect case 6).
*/
again: remove_next = 1 + (end > next->vm_end);//确定是否超过了后驱vma
end = next->vm_end;
anon_vma = next->anon_vma;
importer = vma;
} else if (end > next->vm_start) {/*指定的区域和后驱vma部分重合*/
/*
* vma expands, overlapping part of the next:
* mprotect case 5 shifting the boundary up.
*/
adjust_next = (end - next->vm_start) >> PAGE_SHIFT;
anon_vma = next->anon_vma;
importer = vma;
} else if (end < vma->vm_end) {/*指定的区域没到达后驱vma的结束处*/
/*
* vma shrinks, and !insert tells it's not
* split_vma inserting another: so it must be
* mprotect case 4 shifting the boundary down.
*/
adjust_next = - ((vma->vm_end - end) >> PAGE_SHIFT);
anon_vma = next->anon_vma;
importer = next;
}
}
if (file) {//如果有映射文件
mapping = file->f_mapping;//获取文件对应的address_space
if (!(vma->vm_flags & VM_NONLINEAR))
root = &mapping->i_mmap;
spin_lock(&mapping->i_mmap_lock);
if (importer &&
vma->vm_truncate_count != next->vm_truncate_count) {
/*
* unmap_mapping_range might be in progress:
* ensure that the expanding vma is rescanned.
*/
importer->vm_truncate_count = 0;
}
/*如果指定了待插入的vma,则根据vma是否以非线性的方式映射文件来选择是将
vma插入file对应的address_space的优先树(对应线性映射)还是双向链表(非线性映射)*/
if (insert) {
insert->vm_truncate_count = vma->vm_truncate_count;
/*
* Put into prio_tree now, so instantiated pages
* are visible to arm/parisc __flush_dcache_page
* throughout; but we cannot insert into address
* space until vma start or end is updated.
*/
__vma_link_file(insert);
}
}
/*
* When changing only vma->vm_end, we don't really need
* anon_vma lock.
*/
if (vma->anon_vma && (insert || importer || start != vma->vm_start))
anon_vma = vma->anon_vma;
if (anon_vma) {
spin_lock(&anon_vma->lock);
/*
* Easily overlooked: when mprotect shifts the boundary,
* make sure the expanding vma has anon_vma set if the
* shrinking vma had, to cover any anon pages imported.
*/
if (importer && !importer->anon_vma) {
importer->anon_vma = anon_vma;
__anon_vma_link(importer);//将importer插入importer的anon_vma匿名映射链表中
}
}
if (root) {
flush_dcache_mmap_lock(mapping);
vma_prio_tree_remove(vma, root);
if (adjust_next)
vma_prio_tree_remove(next, root);
}
/*调整vma的相关量*/
vma->vm_start = start;
vma->vm_end = end;
vma->vm_pgoff = pgoff;
if (adjust_next) {//调整后驱vma的相关量
next->vm_start += adjust_next << PAGE_SHIFT;
next->vm_pgoff += adjust_next;
}
if (root) {
if (adjust_next)//如果后驱vma被调整了,则重新插入到优先树中
vma_prio_tree_insert(next, root);
vma_prio_tree_insert(vma, root);//将vma插入到优先树中
flush_dcache_mmap_unlock(mapping);
}
if (remove_next) {//给定区域与后驱vma有重合
/*
* vma_merge has merged next into vma, and needs
* us to remove next before dropping the locks.
*/
__vma_unlink(mm, next, vma);//将后驱vma从红黑树中删除
if (file)//将后驱vma从文件对应的address space中删除
__remove_shared_vm_struct(next, file, mapping);
if (next->anon_vma)//将后驱vma从匿名映射链表中删除
__anon_vma_merge(vma, next);
} else if (insert) {
/*
* split_vma has split insert from vma, and needs
* us to insert it before dropping the locks
* (it may either follow vma or precede it).
*/
__insert_vm_struct(mm, insert);//将待插入的vma插入mm的红黑树,双向链表以及
//匿名映射链表
}
if (anon_vma)
spin_unlock(&anon_vma->lock);
if (mapping)
spin_unlock(&mapping->i_mmap_lock);
if (remove_next) {
if (file) {
fput(file);
if (next->vm_flags & VM_EXECUTABLE)
removed_exe_file_vma(mm);
}
mm->map_count--;
mpol_put(vma_policy(next));
kmem_cache_free(vm_area_cachep, next);
/*
* In mprotect's case 6 (see comments on vma_merge),
* we must remove another next too. It would clutter
* up the code too much to do both in one go.
*/
if (remove_next == 2) {//还有待删除的区域
next = vma->vm_next;
goto again;
}
}
validate_mm(mm);
}
insert_vm_struct()函数用于插入一块新区域
int insert_vm_struct(struct mm_struct * mm, struct vm_area_struct * vma)
{
struct vm_area_struct * __vma, * prev;
struct rb_node ** rb_link, * rb_parent;
/*
* The vm_pgoff of a purely anonymous vma should be irrelevant
* until its first write fault, when page's anon_vma and index
* are set. But now set the vm_pgoff it will almost certainly
* end up with (unless mremap moves it elsewhere before that
* first wfault), so /proc/pid/maps tells a consistent story.
*
* By setting it to reflect the virtual start address of the
* vma, merges and splits can happen in a seamless way, just
* using the existing file pgoff checks and manipulations.
* Similarly in do_mmap_pgoff and in do_brk.
*/
if (!vma->vm_file) {
BUG_ON(vma->anon_vma);
vma->vm_pgoff = vma->vm_start >> PAGE_SHIFT;
}
/*__vma用来保存和vma->start对应的vma(与find_vma()一样),同时获取以下信息:
1.prev用来保存对应的前驱vma
2.rb_link保存该vma区域插入对应的红黑树节点
3.rb_parent保存该vma区域对应的父节点*/
__vma = find_vma_prepare(mm,vma->vm_start,&prev,&rb_link,&rb_parent);
if (__vma && __vma->vm_start < vma->vm_end)
return -ENOMEM;
if ((vma->vm_flags & VM_ACCOUNT) &&
security_vm_enough_memory_mm(mm, vma_pages(vma)))
return -ENOMEM;
vma_link(mm, vma, prev, rb_link, rb_parent);//将vma关联到所有的数据结构中
return 0;
}
static void vma_link(struct mm_struct *mm, struct vm_area_struct *vma,
struct vm_area_struct *prev, struct rb_node **rb_link,
struct rb_node *rb_parent)
{
struct address_space *mapping = NULL;
if (vma->vm_file)//如果存在文件映射则获取文件对应的地址空间
mapping = vma->vm_file->f_mapping;
if (mapping) {
spin_lock(&mapping->i_mmap_lock);
vma->vm_truncate_count = mapping->truncate_count;
}
anon_vma_lock(vma);
/*将vma插入到相应的数据结构中--双向链表,红黑树和匿名映射链表*/
__vma_link(mm, vma, prev, rb_link, rb_parent);
__vma_link_file(vma);//将vma插入到文件地址空间的相应数据结构中
anon_vma_unlock(vma);
if (mapping)
spin_unlock(&mapping->i_mmap_lock);
mm->map_count++;
validate_mm(mm);
}
在创建新的vma区域之前先要寻找一块足够大小的空闲区域,该项工作由get_unmapped_area()函数完成,而实际的工作将会由mm_struct中定义的辅助函数来完成。根据进程虚拟地址空间的布局,会选择使用不同的映射函数,在这里考虑大多数系统上采用的标准函数arch_get_unmapped_area();
unsigned long
arch_get_unmapped_area(struct file *filp, unsigned long addr,
unsigned long len, unsigned long pgoff, unsigned long flags)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma;
unsigned long start_addr;
if (len > TASK_SIZE)
return -ENOMEM;
if (flags & MAP_FIXED)
return addr;
if (addr) {
addr = PAGE_ALIGN(addr);//将地址按页对齐
vma = find_vma(mm, addr);//获取一个vma,该vma可能包含了addr也可能在addr后面并且离addr最近
/*这里确定是否有一块适合的空闲区域,先要保证addr+len不会
超过进程地址空间的最大允许范围,然后如果前面vma获取成功的话则要保证
vma位于addr的后面并且addr+len不会延伸到该vma的区域*/
if (TASK_SIZE - len >= addr &&
(!vma || addr + len <= vma->vm_start))
return addr;
}
/*前面获取不成功的话则要调整起始地址了,根据情况选择缓存的空闲区域地址
或者TASK_UNMAPPED_BASE=TASK_SIZE/3*/
if (len > mm->cached_hole_size) {
start_addr = addr = mm->free_area_cache;
} else {
start_addr = addr = TASK_UNMAPPED_BASE;
mm->cached_hole_size = 0;
}
full_search:
/*从addr开始遍历用户地址空间*/
for (vma = find_vma(mm, addr); ; vma = vma->vm_next) {
/* At this point: (!vma || addr < vma->vm_end). */
if (TASK_SIZE - len < addr) {//这里判断是否已经遍历到了用户地址空间的末端
/*
* Start a new search - just in case we missed
* some holes.
*/
//如果上次不是从TAKS_UNMAPPED_BASE开始遍历的,则尝试从TASK_UNMAPPED_BASE开始遍历
if (start_addr != TASK_UNMAPPED_BASE) {
addr = TASK_UNMAPPED_BASE;
start_addr = addr;
mm->cached_hole_size = 0;
goto full_search;
}
return -ENOMEM;
}
if (!vma || addr + len <= vma->vm_start) {//判断是否有空闲区域
/*
*找到空闲区域的话则记住我们搜索的结束处,以便下次搜索
*/
mm->free_area_cache = addr + len;
return addr;
}
/*该空闲区域不符合大小要求,但是如果这个空闲区域大于之前保存的最大值的话
则将这个空闲区域保存,这样便于前面确定从哪里开始搜索*/
if (addr + mm->cached_hole_size < vma->vm_start)
mm->cached_hole_size = vma->vm_start - addr;
addr = vma->vm_end;
}
}


发表评论

相关推荐
1、ROS-6.44.6-X64-L5-2G-PVE-VMA.zip解压 2、使用WinSCP打开路径/var/lib/vz/dump,上传解压文件vzdump-qemu-666-2019_12_06-20_43_59.vma 3、打开local -> 内容,选中刚才上传的备份文件vzdump-qemu-666-2019_12_...
VMware Management Assistant-vMA6.5 百度网盘地址。
这是功能强大的高级路由器操作系统,使用旨在将你的电脑变成一个专业的路由器,从而进行各方面自定义操作配置,支持添加标准的PC网络接口卡用来增强路由器的功能,routeros基于路由、PPPoE认证、web认证、流量控制...
vMA is a Linux-based vSphere virtual machine that is pre-installed with a command-line interface and select third-party agents needed to manage your vSphere infrastructure. The zip file contains the ....
LMA和VMA,多数情况都是和ld,链接器相关的,详细介绍了LMA和VMA是什么,从你写的源代码到执行你的程序,一般经历了的过程: 源代码编辑 -> 编译 -> 链接 -> 装载 -> 执行
Linux内核VMA-UAF提权突破(CVE-2018-17182) 关于 Google Project Zero的网络安全研究人员发布了详细信息,并针对自内核版本3.16至4.18.8以来Linux内核中存在的高严重性漏洞的概念验证(PoC)漏洞利用。 由白帽...
linux内核使用vm_struct结构体表示映射的地址空间,并且被组织在链表vmlist中,同时为了快速搜索VMA中一块连续的虚拟地址空间采用了红黑树进行管理,另外根据红黑树的层次结构将红黑树的各节点信息保存在vmap_area_...
资源来自pypi官网。 资源全名:vma_nlu-0.0.3.tar.gz
3.6 创建和删除进程的地址空间 156 3.6.1 创建进程的地址空间 156 3.6.2 删除进程的地址空间 175 3.6.3 内核线程1号的地址空间 176 3.7 堆的管理 178 第四章 磁盘文件内存映射 182 4.1 内存映射的数据结构 182 4.2 ...
其中,内核会在进程的虚拟空间查找一块连续的虚拟地址并把虚拟地址的起始和结束地址填充到VMA的vm_start和vm_end字段中,然后调用remap_pfn_range()在页表中建立物理地址与虚拟地址的映射关系。
DDR内存SPD HY5DU1216222CTP-D43颗粒 单面DDR400 512M HYNIX 带序列号。
1.显示进程的虚拟内存地址空间分布信息 2.获取一个进程的虚拟存储区域信息 3.计算vma每个vma区域的大小,以及代码段和数据段的大小. 实验五:proc文件系统及查看进程信息 请读者自己完成一个类似cat的读取程序,可以...
VMA 是基于波动性的动态 MA.
This repository contains the library and example code to work with our VMA430 - gPS MODULE U-BLOX NEO-7M
为了系统的安全性,Linux内核将各个用户进程运行在各自独立的虚拟地址空间,用户进程之间通过虚拟地址空间相互隔离,不能相互访问,一个进程的奔溃不会影响到整个系统的异常也不会干扰到系统以及其他进程运行。Linux...
分步 VHF 适应性 VMA
本实验主要验证和感受感受自己写的代码放在进程地址空间的哪些段中。运行MemoryCheck,需对结果进行仔细观察分析。 任务二: 要求设计实现主流的页面置换算法,在终端可以输入页面数量、内存物理块数、序列长度以及...
Zig-VMA 该项目为Vulkan内存分配器库提供了Zig绑定。 使用这个专案 要使用此库,请首先将vma.zig , vma_config.zig和VulkanMemoryAllocator文件夹复制到您的项目中。 vma_config.zig包含将用于配置项目的构建标志...
2、触发异常的线性地址不处于用户空间的vma中,这种情况得判断是不是因为用户进程的栈空间消耗完而触发的缺页异常,如果是的话则在用户空间对栈区域进行扩展,并且分配相应的物理页,如果不是则作为一次非法地址...